传统的集群安装方式还是比如麻烦,比如说添加新的node节点,需要安装kubelet/proxy,还要配置。kubeadm旨在简化这些繁琐的操作。
环境准备
docker版本为:1.12.6
kubeadm版本为:v1.7.5
| 主机IP | 主机名称 | 内存 |
|---|---|---|
| 192.168.10.6 | k8s-master | 1024m |
| 192.168.10.7 | k8s-node1 | 1024m |
| 192.168.10.8 | k8s-node2 | 1024m |
系统优化1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61sed -i 's;SELINUX=.*;SELINUX=disabled;' /etc/selinux/config
setenforce 0
getenforce
#LANG="en_US.UTF-8"
sed -i 's;LANG=.*;LANG="zh_CN.UTF-8";' /etc/locale.conf
cat /etc/NetworkManager/NetworkManager.conf|grep "dns=none" > /dev/null
if [[ $? != 0 ]]; then
echo "dns=none" >> /etc/NetworkManager/NetworkManager.conf
systemctl restart NetworkManager.service
fi
systemctl disable iptables
systemctl stop iptables
systemctl disable firewalld
systemctl stop firewalld
#ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
timedatectl set-timezone Asia/Shanghai
#logined limit
cat /etc/security/limits.conf|grep 100000 > /dev/null
if [[ $? != 0 ]]; then
cat >> /etc/security/limits.conf << EOF
* - nofile 100000
* - nproc 100000
EOF
fi
sed -i 's;4096;100000;g' /etc/security/limits.d/20-nproc.conf
#systemd service limit
cat /etc/systemd/system.conf|egrep '^DefaultLimitCORE' > /dev/null
if [[ $? != 0 ]]; then
cat >> /etc/systemd/system.conf << EOF
DefaultLimitCORE=infinity
DefaultLimitNOFILE=100000
DefaultLimitNPROC=100000
EOF
fi
cat /etc/sysctl.conf|grep "net.ipv4.ip_local_port_range" > /dev/null
if [[ $? != 0 ]]; then
cat >> /etc/sysctl.conf << EOF
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 300
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.ip_forward = 1
EOF
sysctl -p
fi
su - root -c "ulimit -a"
# 同步时间
yum -y install ntp
systemctl start ntpd
systemctl enable ntpd
修改主机名1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23#192.168.10.6
hostnamectl --static set-hostname k8s-master
sysctl kernel.hostname=k8s-master
echo '192.168.10.6 k8s-master
192.168.10.7 k8s-node1
192.168.10.8 k8s-node2' >> /etc/hosts
#192.168.10.7
hostnamectl --static set-hostname k8s-node1
sysctl kernel.hostname=k8s-node1
echo '192.168.10.6 k8s-master
192.168.10.7 k8s-node1
192.168.10.8 k8s-node2' >> /etc/hosts
#192.168.10.8
hostnamectl --static set-hostname k8s-node2
sysctl kernel.hostname=k8s-node2
echo '192.168.10.6 k8s-master
192.168.10.7 k8s-node1
192.168.10.8 k8s-node2' >> /etc/hosts
修改系统参数1
2
3
4
5
6
7cat >> /etc/sysctl.d/k8s.conf << EOF
#k8s
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
安装
yum安装
每台添加yum源:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# docker repo
tee /etc/yum.repos.d/docker.repo <<-'EOF'
[docker-repo]
name=Docker Repository
baseurl=https://mirrors.aliyun.com/docker-engine/yum/repo/main/centos/7/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-engine/yum/gpg
EOF
# k8s repo
tee /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes-repo]
name=Kubernetes Repository
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF
yum安装:1
2
3
4yum install -y docker-engine-1.12.6-1.el7.centos.x86_64
#yum install -y kubelet kubectl kubernetes-cni kubeadm
yum install -y kubernetes-cni-0.5.1-0.x86_64 kubelet-1.7.5-0.x86_64 kubectl-1.7.5-0.x86_64 kubeadm-1.7.5-0.x86_64
systemctl enable kubelet
二进制安装:1
wget https://dl.k8s.io/v1.7.5/kubernetes-server-linux-amd64.tar.gz
下载镜像
镜像列表
1 | docker pull gcr.io/google_containers/kube-proxy-amd64:v1.7.5 |
注意:以上镜像在创建时会自动下载,无需手动下载。以上镜像需要先翻墙才行。
master初始化
初始化
统一docker与kubernetes的driver:
可以直接执行以下命令修改:1
sed -i 's;systemd;cgroupfs;g' /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
保存配置, 重启:1
2systemctl daemon-reload
systemctl restart kubelet
kubeadmn创建的etcd为单节点,不建议使用。建议使用外部的etcd集群。具体安装请参考etcd集群安装
v1.6.x版本后,–external-etcd-endpoints参数已不能使用。所以要使用–config参数外挂配置文件kubeadm-config.yml:1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration
api:
advertiseAddress: 192.168.10.6
networking:
#dnsDomain: myk8s.com
podSubnet: 10.244.0.0/16
etcd:
endpoints:
- http://192.168.10.6:2379
- http://192.168.10.7:2379
- http://192.168.10.8:2379
kubernetesVersion: v1.7.5
具体请参考:kubeadm-config.yml
注意:最好不要修改dnsDomain,不然会有一些奇怪的问题。
初始化
在master上执行:1
kubeadm init --config kubeadm-config.yml
另外一种初始化方式1
2
3
4
5#export KUBE_COMPONENT_LOGLEVEL='--v=0'
kubeadm init --kubernetes-version=v1.7.5 --apiserver-advertise-address=192.168.10.6
#如果是使用flannel网络的话,要加上--pod-network-cidr 10.244.0.0/16
kubeadm init --kubernetes-version=v1.7.5 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.10.6
异常处理
初始化时, 会发现卡死不动, 可以通过系统日志查看错误
1 | journalctl -f -u kubelet.server |
这个是K8S v1.6.x的一个变化, 文件驱动与docker使用的文件驱动不一致, 导致镜像无法启动。
此处可以修改kubelet的文件驱动,请参考http://www.jianshu.com/p/02dc13d2f651
先确认docker的Cgroup Driver:1
2
3[root@k8s-node1 ~]# docker info
......
Cgroup Driver: cgroupfs
需要将kubeadm.conf的systemd修改为cgroupfs。注意: 每台都要修改:
1 | # 进入kubelet启动配置文件 |
将1
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd"
替换为:1
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"
可以直接执行以下命令修改:1
sed -i 's;systemd;cgroupfs;g' /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
保存配置, 重启:1
2systemctl daemon-reload
systemctl restart kubelet
然后再重新初始化
在master上执行:1
2
3kubeadm reset
#kubeadm init --kubernetes-version=v1.7.5 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.10.6
kubeadm init --config kubeadm-config.yml
kubeadm init时出现
1 | [apiclient] Temporarily unable to list nodes (will retry) |
应该是dns server把localhost解析到其他地址去了。可以通过nslookup 命令验证:
[root@master ~]# nslookup localhost
修改的/etc/resolv.conf中的search内容后问题解决。
configmaps “cluster-info” already exists
需要清理etcd数据:1
2
3systemctl stop etcd
rm -fr /var/lib/etcd/etcd/*
systemctl restart etcd
正常情况下,应该能显示以下的日志:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44kubeadm init --kubernetes-version=v1.7.5 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.10.6
[kubeadm] WARNING: kubeadm is in beta, please do not use it for production clusters.
[init] Using Kubernetes version: v1.7.5
[init] Using Authorization mode: RBAC
[preflight] Running pre-flight checks
[preflight] WARNING: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Starting the kubelet service
[certificates] Generated CA certificate and key.
[certificates] Generated API server certificate and key.
[certificates] API Server serving cert is signed for DNS names [k8s-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.10.6]
[certificates] Generated API server kubelet client certificate and key.
[certificates] Generated service account token signing key and public key.
[certificates] Generated front-proxy CA certificate and key.
[certificates] Generated front-proxy client certificate and key.
[certificates] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[apiclient] Created API client, waiting for the control plane to become ready
[apiclient] All control plane components are healthy after 126.837475 seconds
[apiclient] Waiting for at least one node to register
[apiclient] First node has registered after 6.516528 seconds
[token] Using token: 67a477.959aa53030fd8444
[apiconfig] Created RBAC rules
[addons] Created essential addon: kube-proxy
[addons] Created essential addon: kube-dns
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run (as a regular user):
sudo cp /etc/kubernetes/admin.conf $HOME/
sudo chown $(id -u):$(id -g) $HOME/admin.conf
export KUBECONFIG=$HOME/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join --token 67a477.959aa53030fd8444 192.168.10.6:6443
之前的版本, 当我们初始化成功之后, 会发现token不会保留, 如果一旦没有记录下来, 其他节点就没法加入了, 这里添加了kubeadm token命令1
2
3kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION
67a477.959aa53030fd8444 <forever> <never> authentication,signing The default bootstrap token generated by 'kubeadm init'.
默认情况下, master节点是不会调度pod, 也就是说, 只有一台主机的情况下, 我们无法启动pod, 但有的时候我们的确只有一台机器, 这个时候可以执行命令, 允许master调度pod(这个命令和1.5.x版本不一样)1
kubectl taint nodes --all node-role.kubernetes.io/master-
查询node情况
1 | kubectl --kubeconfig=/etc/kubernetes/admin.conf get nodes |
kubectl 命令
这个命令是我们经常使用的, 几乎所有的k8s相关操作都需要, 但当我们集群安装好后, 发现这个命令会报错。
最直接的方法是带上参数 –kubeconfig1
kubectl --kubeconfig=/etc/kubernetes/admin.conf get nodes
注意:
只有master中才有admin.conf文件,另外node上只有kubelet.conf。所以只能在master进行logs/exec等命令。
可以将admin.conf拷贝到其他node机器中:1
2scp /etc/kubernetes/admin.conf root@192.168.10.7:/etc/kubernetes/
scp /etc/kubernetes/admin.conf root@192.168.10.8:/etc/kubernetes/
如果不想每次都带上参数, 可以配置环境变量1
2
3
4# 添加
tee >> ~/.bash_profile << EOF
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
执行1
source ~/.bash_profile
这样就可以不用带–kubeconfig参数了1
kubectl get nodes
node加入
加入node到集群中
请记得init后的join命令(类似于下面,但token不一样),其他的node要加入集群的话,必须用下面的命令:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22kubeadm join --token 67a477.959aa53030fd8444 192.168.10.6:6443
[kubeadm] WARNING: kubeadm is in beta, please do not use it for production clusters.
[preflight] Running pre-flight checks
[preflight] WARNING: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Starting the kubelet service
[discovery] Trying to connect to API Server "192.168.10.6:6443"
[discovery] Created cluster-info discovery client, requesting info from "https://192.168.10.6:6443"
[discovery] Cluster info signature and contents are valid, will use API Server "https://192.168.10.6:6443"
[discovery] Successfully established connection with API Server "192.168.10.6:6443"
[bootstrap] Detected server version: v1.7.5
[bootstrap] The server supports the Certificates API (certificates.k8s.io/v1beta1)
[csr] Created API client to obtain unique certificate for this node, generating keys and certificate signing request
[csr] Received signed certificate from the API server, generating KubeConfig...
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
Node join complete:
* Certificate signing request sent to master and response
received.
* Kubelet informed of new secure connection details.
Run 'kubectl get nodes' on the master to see this machine join.
查看node信息1
2
3
4
5 kubectl get no
NAME STATUS AGE VERSION
k8s-master NotReady 39m v1.7.5
k8s-node1 NotReady 32s v1.7.5
k8s-node2 NotReady 53s v1.7.5
异常处理
node加入后,STATUS状态为:NotReady
查看kubelet日志:1
2systemctl status -l kubelet
kubeadm network plugin is not ready: cni config uninitialized
如果采用了非cni方式部署flannel网络,需要去掉cni网络参数,参考https://github.com/kubernetes/kubernetes/issues/43815:
you need to edit /etc/systemd/system/kubelet.service.d/10-kubeadm.conf1
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_SYSTEM_PODS_ARGS $KUBELET_NETWORK_ARGS $KUBELET_DNS_ARGS $KUBELET_AUTHZ_ARGS $KUBELET_EXTRA_ARGS
remove $KUBELET_NETWORK_ARGS, and then restart kubelet after that kubeadm init should work.
重启kubelet服务后正常:1
2systemctl daemon-reload
systemctl restart kubelet
查看pod信息:
1 | [root@k8s-master v1.7.5]# kubectl get pod -o wide -n kube-system |
不能查看pod日志
报以下的错误:1
2kubectl logs kube-dns-1783747724-bh3g3 -n kube-system
Error from server (BadRequest): a container name must be specified for pod kube-dns-1783747724-bh3g3, choose one of: [kubedns dnsmasq sidecar]
这个是因为为kubectl没有admin权限,所以需要修改~/.bash_profile中的1
export KUBECONFIG=/etc/kubernetes/admin.conf
执行1
source ~/.bash_profile
kube-dns是不能正常运行的,STATUS为Pending
这是因为没有部署网络,具体请参考部署网络1
2
3
4
5
6
7
8
9
10[root@k8s-master ~]# kubectl get pod -o wide -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE
etcd-k8s-master 1/1 Running 0 37m 192.168.10.6 k8s-master
kube-apiserver-k8s-master 1/1 Running 0 37m 192.168.10.6 k8s-master
kube-controller-manager-k8s-master 1/1 Running 0 37m 192.168.10.6 k8s-master
kube-dns-3913472980-gx5zn 0/3 Pending 0 42m <none>
kube-proxy-3970g 1/1 Running 0 4m 192.168.10.8 k8s-node2
kube-proxy-t8zhh 1/1 Running 0 42m 192.168.10.6 k8s-master
kube-proxy-xvsdk 1/1 Running 0 3m 192.168.10.7 k8s-node1
kube-scheduler-k8s-master 1/1 Running 0 37m 192.168.10.6 k8s-master
部署网络
cni网络
1 | wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml |
如果是使用vagrant,需要修改kube-flannel.yml:1
command: [ "/opt/bin/flanneld", "--iface=eth1", "--ip-masq", "--kube-subnet-mgr" ]
参考修改后的文件:kube-flannel.yml
创建网络:
1 | kubectl create -f kube-flannel.yml |
flannel网络
也可以手动部署flannel网络,这种为非cni网络。具体请参考使用Flannel搭建docker网络
需要去掉cni网络:
1 | sed -i 's;$KUBELET_NETWORK_ARGS ;;g' /etc/systemd/system/kubelet.service.d/10-kubeadm.conf |
测试dns
#https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/
Create a file named busybox.yaml with the following contents:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16tee busybox.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
EOF
Then create a pod using this file:1
kubectl create -f busybox.yaml
测试:1
2
3
4
5
6
7
8
9#kubectl run busybox --rm -ti --image=busybox --restart=Never -- nslookup -type=srv kubernetes
#以上每次退出后会自动删除images中的镜像,每次执行都会重新下载image,所以每次执行都会有些慢。
[root@k8s-master config]# kubectl exec -ti busybox -- nslookup kubernetes.default
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
dashboard
安装
最新方式
https://forums.docker.com/t/docker-for-mac-kubernetes-dashboard/44116/6
1 | kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/alternative/kubernetes-dashboard.yaml |
Then, open your browser on http://127.0.0.1:9090 12 and the dashboard should work without any authentification!
或者:1
kubectl proxy
如果不能访问看是不是为http:kubernetes-dashboard,如果是https:kubernetes-dashboard的话会报Error: ‘tls: oversized record received with length 20527’的错误。
see: https://github.com/kubernetes/dashboard/wiki/Accessing-Dashboard---1.7.X-and-above
其他方式
1 | #1.6.3版本已经不能下载了 |
1.6请参考:kubernetes-dashboard.yaml
1.7请参考:kubernetes-dashboard.yaml
查看
1 | kubectl get pod,svc -n kube-system -l k8s-app=kubernetes-dashboard |
访问
第1种访问方式
https://192.168.10.6:6443/ui
https://192.168.10.6:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
注意:1.7版本后https://192.168.10.6:6443/ui已不能访问。否则访问时会出现以下错误:
Error: ‘malformed HTTP response “\x15\x03\x01\x00\x02\x02”‘
Trying to reach: ‘http://10.244.2.6:8443/'
参考http://tonybai.com/2017/09/26/some-notes-about-deploying-kubernetes-dashboard-1-7-0/
访问该地址后,我们在浏览器中看到如下登录页面:
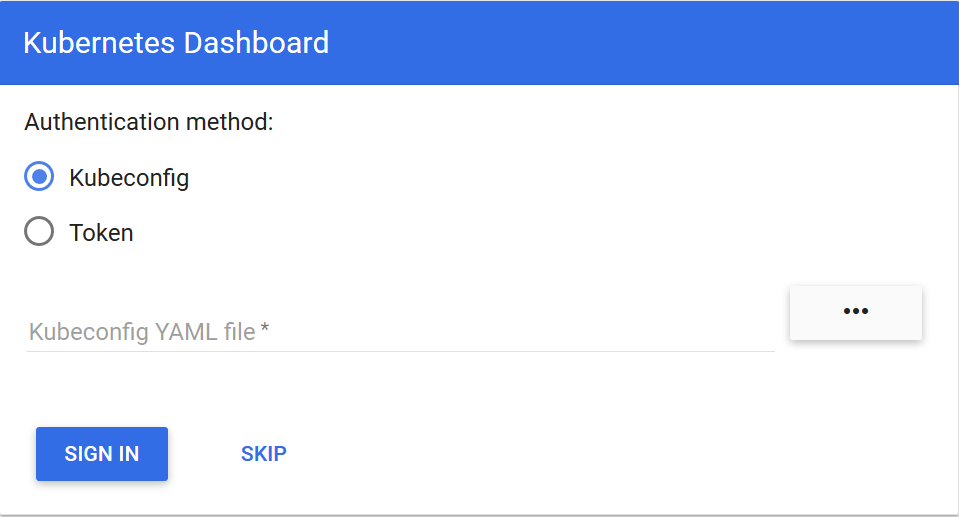
dashboard v1.7默认支持两种身份校验登录方式:kubeconfig和token两种。
我们说说token这种方式。点击选择:Token单选框,提示你输入token。可以通过以下方式获取token:
1 | [root@k8s-master ~]# kubectl get secret -n kube-system|grep dashboard |
登录后出现: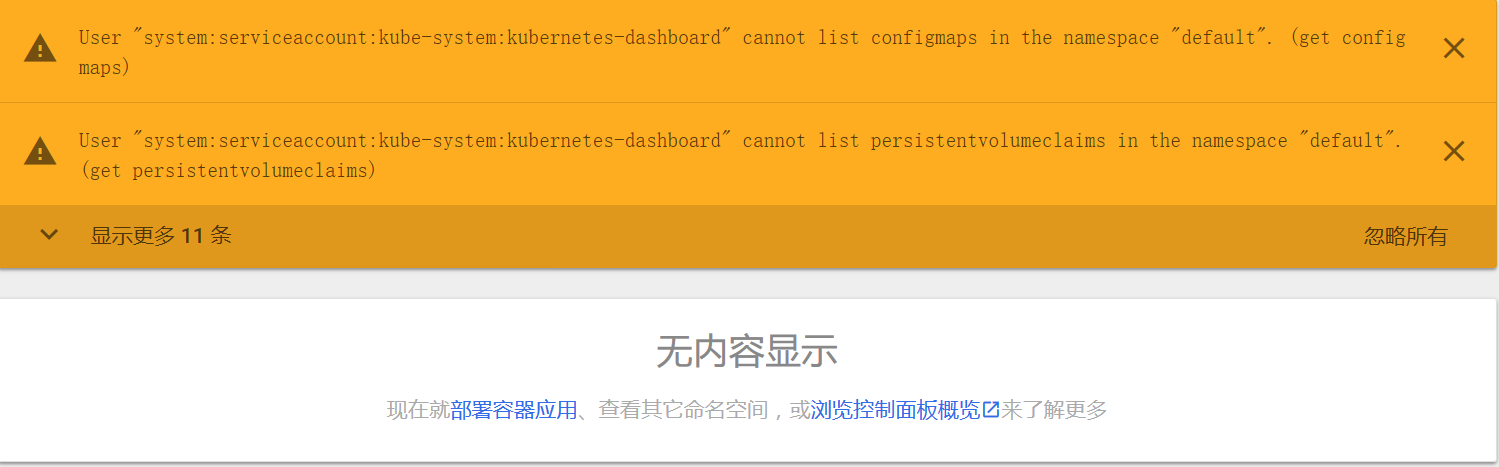
这个是由于1.7后,默认为最小权限。需要创建权限:
参考official-release
1 | tee dashboard-admin.yaml << EOF |
让Dashboard v1.7.0支持basic auth login方式:
我们要用basic auth方式登录dashboard,需要对kubernetes-dashboard.yaml进行如下修改:
1 | args: |
重新创建即可。
第2种访问方式
http://192.168.10.6:9090/ui
http://192.168.10.6:8443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
可以通过kubectl proxy代理访问:
1 | [root@k8s-master ~]# kubectl get ep -n kube-system |
这样就可以访问了。此访问为非安全方式,如果提示输入密码或者token时,直接SKIP就可以了。
可能会出现pod为error的错误,将所有的dashboard yaml重新创建一下就可以了。
注意:如果是1.6版本,访问地址为:http://192.168.10.6:9090/ui
1.6版本还可以通过NodePort方式访问,但1.7版本不行:
参考:
https://github.com/qianlei90/Blog/issues/28
https://github.com/kubernetes/dashboard/issues/692
因为使用kubeadm安装的集群是不带认证的,所以无法直接从https://1
2
3
4
5
6spec:
type: NodePort
ports:
- port: 80
targetPort: 9090
nodePort: 30000
异常处理
User “system:anonymous” cannot get at the cluster scope
参考http://www.tongtongxue.com/archives/16338.html
编辑/etc/kubernetes/manifests/kube-apiserver.yaml,添加- –anonymous-auth=false:1
2
3
4
5spec:
containers:
- command:
- kube-apiserver
- --anonymous-auth=false
kube-apiserver周期性异常重启:1
2kubectl describe pod kube-apiserver-k8s-master -n kube-system|grep health
Liveness: http-get https://127.0.0.1:6443/healthz delay=15s timeout=15s period=10s #success=1 #failure=8
可以看到liveness check有8次failure!8次是kube-apiserver的failure门槛值,这个值在/etc/kubernetes/manifests/kube-apiserver.yaml中我们可以看到:1
2
3
4
5
6
7
8
9livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 6443
scheme: HTTPS
initialDelaySeconds: 15
timeoutSeconds: 15
这样,一旦failure次数超限,kubelet会尝试Restart kube-apiserver,这就是问题的原因。那么为什么kube-apiserver的 liveness check 会fail呢?这缘于我们关闭了匿名请求的身份验证权。还是来看/etc/kubernetes/manifests/kube-apiserver.yaml中的livenessProbe段,对于kube-apiserver来说,kubelet会通过访问: https://127.0.0.1:6443/healthz的方式去check是否ok?并且kubelet使用的是anonymous requests。由于上面我们已经关闭了对anonymous-requests的身份验证权,kubelet就会一直无法访问kube-apiserver的/healthz端点,导致kubelet认为kube-apiserver已经死亡,并尝试重启它。
调整/healthz检测的端点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19spec:
containers:
- command:
- kube-apiserver
- --anonymous-auth=false
... ...
- --insecure-bind-address=127.0.0.1
- --insecure-port=8080
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 15
timeoutSeconds: 15
... ...
我们不再用anonymous-requests,但我们可以利用–insecure-bind-address和–insecure-port。让kubelet的请求到insecure port,而不是secure port。由于insecure port的流量不会受到身份验证、授权等功能的限制,因此可以成功probe到kube-apiserver的liveness,kubelet不会再重启kube-apiserver了。
重启kubelet服务:1
systemctl restart kubelet
Unauthorized
参考http://tonybai.com/2017/07/20/fix-cannot-access-dashboard-in-k8s-1-6-4/
k8s 1.6.x版本与1.5.x版本的一个很大不同在于1.6.x版本启用了RBAC的Authorization mode(授权模型),但我们依旧通过basic auth方式进行apiserver的Authentication,而不是用客户端数字证书校验等其他方式:1
2
3
4
5
6
7spec:
containers:
- command:
- kube-apiserver
... ...
- --basic-auth-file=/etc/kubernetes/basic_auth_file
... ...
添加basic_auth_file内容:1
echo "admin,admin,2017" > /etc/kubernetes/basic_auth_file
basic_auth_file格式为:1
password,username,uid
参考完整的/etc/kubernetes/manifests/kube-apiserver.yaml内容:
主要添加了以下内容:1
2
3
4
5
6
7
8
9- --anonymous-auth=false
- --basic-auth-file=/etc/kubernetes/basic_auth_file
- --insecure-bind-address=127.0.0.1
- --insecure-port=8080
host: 127.0.0.1
path: /healthz
port: 8080
scheme: HTTP
完整的内容:
1 | apiVersion: v1 |
User “admin” cannot get at the cluster scope
admin这个user并未得到足够的授权。这里我们要做的就是给admin选择一个合适的clusterrole。但kubectl并不支持查看user的信息,初始的clusterrolebinding又那么多,一一查看十分麻烦。我们知道cluster-admin这个clusterrole是全权限的,我们就来将admin这个user与clusterrole: cluster-admin bind到一起:1
kubectl create clusterrolebinding login-on-dashboard-with-cluster-admin --clusterrole=cluster-admin --user=admin
重启kubelet服务后问题解决:1
systemctl restart kubelet
访问https://192.168.10.6:6443/ui,用admin/admin就可以正常登录了。
heapster插件部署
安装
下面安装Heapster为集群添加使用统计和监控功能,为Dashboard添加仪表盘。 使用InfluxDB做为Heapster的后端存储,开始部署:1
2
3
4
5
6
7
8mkdir -p ~/k8s/heapster
cd ~/k8s/heapster
wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/grafana.yaml
wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/rbac/heapster-rbac.yaml
wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/heapster.yaml
wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/influxdb.yaml
kubectl create -f ./
或者
1 | wget https://github.com/kubernetes/heapster/archive/v1.4.2.zip |
具体可参考heapster.zip
如果是通过heapster.zip创建的话,因为有修改一些内容,需要执行:1
2kubectl create configmap influxdb-config --from-file=config.toml -n kube-system
kubectl create -f ./
访问地址:
cAdvisor:
http://192.168.10.6:4194/
http://192.168.10.7:4194/
http://192.168.10.8:4194/
注意:1.7版本cAdvisor已不能访问,可以手动在每台机器上安装cAdvisor:1
2
3
4
5
6
7
8
9
10docker run --restart=always \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=4194:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest
grafana:https://192.168.10.6:6443/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana/
http://192.168.10.6:30015/
influxdb:https://192.168.10.6:6443/api/v1/proxy/namespaces/kube-system/services/monitoring-influxdb
http://192.168.10.6:8083/
最后确认所有的pod都处于running状态,打开Dashboard,集群的使用统计会以仪表盘的形式显示出来。
异常处理
ErrImagePull
查看pod状态:1
2
3
4
5
6
7
8
9
10
11
12
13[root@k8s-master temp]# kubectl get pod -o wide -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE
heapster-1528902802-hjjh8 1/1 Running 0 13s 10.244.66.3 k8s-node2
kube-apiserver-k8s-master 1/1 Running 3 20h 192.168.10.6 k8s-master
kube-controller-manager-k8s-master 1/1 Running 27 21h 192.168.10.6 k8s-master
kube-dns-1783747724-3jb47 3/3 Running 3 4h 10.244.100.2 k8s-node1
kube-proxy-3l1wf 1/1 Running 8 2d 192.168.10.7 k8s-node1
kube-proxy-5mwcl 1/1 Running 10 2d 192.168.10.8 k8s-node2
kube-proxy-s02wm 1/1 Running 7 2d 192.168.10.6 k8s-master
kube-scheduler-k8s-master 1/1 Running 27 21h 192.168.10.6 k8s-master
kubernetes-dashboard-2315583659-qt0vm 1/1 Running 13 1d 10.244.100.3 k8s-node1
monitoring-grafana-973508798-wg055 0/1 ErrImagePull 0 13s 10.244.66.2 k8s-node2
monitoring-influxdb-3871661022-jvpt9 0/1 ErrImagePull 0 12s 10.244.100.4 k8s-node1
发现grafana与influxdb状态为ErrImagePull,查看monitoring-grafana-973508798-wg055给你monitoring-influxdb-3871661022-jvpt9日志:1
2kubectl describe pod monitoring-influxdb-3871661022-jvpt9 -n kube-system
1m 10s 4 kubelet, k8s-node1 Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "influxdb" with ErrImagePull: "rpc error: code = 2 desc = Error: Status 405 trying to pull repository google_containers/heapster-influxdb-amd64: \"v1 Registry API is disabled. If you are not explicitly using the v1 Registry API, it is possible your v2 image could not be found. Verify that your image is available, or retry with `dockerd --disable-legacy-registry`. See https://cloud.google.com/container-registry/docs/support/deprecation-notices\""
应该是images的版本在registry中找不到。修改grafana.yaml与influxdb.yaml中image的路径:1
2
3
4
5
6
7#grafana.yaml
#image: gcr.io/google_containers/heapster-grafana-amd64:v4.4.3
image: gcr.io/google_containers/heapster-grafana-amd64:v4.0.2
#influxdb.yaml
#image: gcr.io/google_containers/heapster-influxdb-amd64:v1.3.3
image: gcr.io/google_containers/heapster-influxdb-amd64:v1.1.1
删除后重新创建正常:1
2kubectl delete -f ./
kubectl create -f ./
cannot list nodes at the cluster scope
查看日志:1
2kubectl logs -f --tail 100 heapster-1528902802-6kzfk -n kube-system
E0903 07:09:35.016005 1 reflector.go:190] k8s.io/heapster/metrics/util/util.go:51: Failed to list *v1.Node: User "system:serviceaccount:kube-system:heapster" cannot list nodes at the cluster scope. (get nodes)
这个是由于rbac问题,需要执行:1
kubectl create -f heapster-rbac.yaml
ServiceUnavailable
请等待kubernetes创建完成即可。
grafana: Problem! the server could not find the requested resource
当访问https://192.168.10.6:6443/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana/时,出现Problem! the server could not find the requested resource。两种方案解决:
方案1:
修改grafana.yaml:1
2#value: /
value: /api/v1/proxy/namespaces/kube-system/services/monitoring-grafana/
重新创建grafana:1
2kubectl delete -f grafana.yaml
kubectl create -f grafana.yaml
访问https://192.168.10.6:6443/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana,正常。
方案2:
修改grafana.yaml:1
2
3
4
5
6
7
8
9
10
11
12
13spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
ports:
- port: 3000
targetPort: 3000
selector:
k8s-app: grafana
#externalIPs:
#- 192.168.10.6
访问http://192.168.10.6:3000,正常。
或者:1
2
3
4
5
6
7
8
9
10
11
12spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
type: NodePort
ports:
- port: 80
targetPort: 3000
nodePort: 30015
selector:
k8s-app: grafana
访问http://192.168.10.6:30015,正常。
influxdb 404 page not found
访问https://192.168.10.6:6443/api/v1/proxy/namespaces/kube-system/services/monitoring-influxdb时出现404 page not found,这是因为influxdb 官方建议使用命令行或 HTTP API 接口来查询数据库,从 v1.1.0 版本开始默认关闭 admin UI,将在后续版本中移除 admin UI 插件。解决方案如下:
下载config.toml:1
2
3
4
5
6
7
8
9
10
11
12wget https://raw.githubusercontent.com/kubernetes/heapster/master/influxdb/config.toml
添加:
[admin]
enabled = true
bind-address = ":8083"
https-enabled = false
https-certificate = "/etc/ssl/influxdb.pem"
# 将修改后的配置写入到 ConfigMap 对象中
#kubectl delete configmap influxdb-config -n kube-system
kubectl create configmap influxdb-config --from-file=config.toml -n kube-system
修改influxdb.yaml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: influxdb
spec:
containers:
- name: influxdb
#image: gcr.io/google_containers/heapster-influxdb-amd64:v1.3.3
image: gcr.io/google_containers/heapster-influxdb-amd64:v1.1.1
volumeMounts:
- mountPath: /data
name: influxdb-storage
- mountPath: /etc/
name: influxdb-config
volumes:
- name: influxdb-storage
emptyDir: {}
- name: influxdb-config
configMap:
name: influxdb-config
...
...
spec:
ports:
- name: http
port: 8083
targetPort: 8083
- name: api
port: 8086
targetPort: 8086
selector:
k8s-app: influxdb
externalIPs:
- 192.168.10.6
重新创建influxdb:1
2kubectl delete -f influxdb.yaml
kubectl create -f influxdb.yaml
访问http://192.168.10.6:8083,正常。
或者:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: influxdb
spec:
containers:
- name: influxdb
#image: gcr.io/google_containers/heapster-influxdb-amd64:v1.3.3
image: gcr.io/google_containers/heapster-influxdb-amd64:v1.1.1
volumeMounts:
- mountPath: /data
name: influxdb-storage
- mountPath: /etc/
name: influxdb-config
volumes:
- name: influxdb-storage
emptyDir: {}
- name: influxdb-config
configMap:
name: influxdb-config
...
...
spec:
type: "NodePort"
ports:
- name: http
port: 8083
targetPort: 8083
nodePort: 30016
- name: api
port: 8086
targetPort: 8086
selector:
k8s-app: influxdb
重新创建influxdb:1
2kubectl delete -f influxdb.yaml
kubectl create -f influxdb.yaml
访问http://192.168.10.6:30016,正常。
重新创建influxdb:1
2kubectl delete -f influxdb.yaml
kubectl create -f influxdb.yaml
访问http://192.168.10.6:8083,正常。
efk插件插件部署
安装
1 | git clone https://github.com/kubernetes/kubernetes.git |
进入源码的kubernetes/cluster/addons/fluentd-elasticsearch目录,需要定义了 elasticsearch 和 fluentd 使用的 Role 和 RoleBinding。添加es-rbac.yaml与fluentd-es-rbac.yaml两个文件:
es-rbac.yml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20apiVersion: v1
kind: ServiceAccount
metadata:
name: elasticsearch
namespace: kube-system
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1alpha1
metadata:
name: elasticsearch
subjects:
- kind: ServiceAccount
name: elasticsearch
namespace: kube-system
roleRef:
kind: ClusterRole
name: view
apiGroup: rbac.authorization.k8s.io
fluentd-es-rbac.yaml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-system
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1alpha1
metadata:
name: fluentd
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-system
roleRef:
kind: ClusterRole
name: view
apiGroup: rbac.authorization.k8s.io
修改es-controller.yaml,添加serviceAccountName:1
2
3
4spec:
serviceAccountName: elasticsearch
containers:
- image: gcr.io/google_containers/elasticsearch:v2.4.1-2
修改fluentd-es-ds.yaml,添加serviceAccountName:1
2
3
4
5spec:
serviceAccountName: fluentd
containers:
- name: fluentd-es
image: gcr.io/google_containers/fluentd-elasticsearch:1.22
给 Node 设置标签:
DaemonSet fluentd-es-v1.22 只会调度到设置了标签 beta.kubernetes.io/fluentd-ds-ready=true 的 Node,需要在期望运行 fluentd 的 Node 上设置该标签;1
2
3
4
5
6$ kubectl get nodes
NAME STATUS AGE VERSION
k8s-node1 Ready 1d v1.7.5
$ kubectl label nodes k8s-node1 beta.kubernetes.io/fluentd-ds-ready=true
$ kubectl label nodes k8s-node2 beta.kubernetes.io/fluentd-ds-ready=true
创建:1
kubectl create -f ./
具体文件可参考EFK.zip
访问Kibana:
地址为:https://192.168.10.6:6443/api/v1/proxy/namespaces/kube-system/services/kibana-logging
如果出现Error: ‘dial tcp 10.244.2.5:5601: connection refused的错误:
查询kibana-logging日志:1
2
3
4[root@k8s-master EFK]# kubectl logs kibana-logging-3757371098-bjrlh -n kube-system
ELASTICSEARCH_URL=http://elasticsearch-logging:9200
server.basePath: /api/v1/proxy/namespaces/kube-system/services/kibana-logging
{"type":"log","@timestamp":"2017-09-04T09:28:51Z","tags":["info","optimize"],"pid":5,"message":"Optimizing and caching bundles for kibana and statusPage. This may take a few minutes"}
请耐心等待kibana后台完成即可。
prometheus监控
安装
参考kubernetes-prometheus1
2wget https://raw.githubusercontent.com/giantswarm/kubernetes-prometheus/master/manifests-all.yaml
kubectl create -f manifests-all.yaml
配置文件请参考:prometheus.zip
More Dashboards
以下已经自动添加,无需再手动添加。
See grafana.net for some example dashboards and plugins.
Configure Prometheus data source for Grafana.
Grafana UI / Data Sources / Add data source
Name: prometheus
Type: Prometheus
Url: http://prometheus:9090
Add
Import Prometheus Stats:
Grafana UI / Dashboards / Import
Grafana.net Dashboard: https://grafana.net/dashboards/2
Load
Prometheus: prometheus
Save & Open
Import Kubernetes cluster monitoring:
Grafana UI / Dashboards / Import
Grafana.net Dashboard: https://grafana.net/dashboards/162
Load
Prometheus: prometheus
Save & Open
访问地址:1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@k8s-node1 ~]# kubectl get svc,ep -n monitoring
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/alertmanager 10.111.106.237 <nodes> 9093:30582/TCP 14h
svc/grafana 10.108.245.18 <nodes> 3000:30718/TCP 14h
svc/kube-state-metrics 10.109.29.182 <none> 8080/TCP 14h
svc/prometheus 10.101.186.72 <nodes> 9090:32617/TCP 14h
svc/prometheus-node-exporter None <none> 9100/TCP 14h
NAME ENDPOINTS AGE
ep/alertmanager 10.244.100.6:9093 14h
ep/grafana 10.244.100.8:3000 14h
ep/kube-state-metrics 10.244.100.9:8080,10.244.15.4:8080 14h
ep/prometheus 10.244.15.5:9090 14h
ep/prometheus-node-exporter 192.168.10.6:9100,192.168.10.7:9100 14h
可以看到:
prometheus: http://192.168.10.6:32617
grafana: http://192.168.10.6:30718
状态查询
查看集群状态
1 | kubectl cluster-info |
查看所有信息:
1 | #kubectl get pod,svc,ep -o wide -n kube-system |
参考
http://zerosre.com/2017/05/11/k8s%E6%96%B0%E7%89%88%E6%9C%AC%E5%AE%89%E8%A3%85/
http://www.tongtongxue.com/archives/16338.html
http://tonybai.com/2017/07/20/fix-cannot-access-dashboard-in-k8s-1-6-4/
http://blog.frognew.com/2017/04/install-ha-kubernetes-1.6-cluster.html
http://blog.frognew.com/2017/04/kubeadm-install-kubernetes-1.6.html
http://blog.frognew.com/2017/07/kubeadm-install-kubernetes-1.7.html
https://cloudnil.com/2017/07/10/Deploy-kubernetes1.6.7-with-kubeadm/
https://www.centos.bz/2017/05/centos-7-kubeadm-install-k8s-kubernetes/
http://leonlibraries.github.io/2017/06/15/Kubeadm%E6%90%AD%E5%BB%BAKubernetes%E9%9B%86%E7%BE%A4/
http://www.jianshu.com/p/60069089c981
https://github.com/opsnull/follow-me-install-kubernetes-cluster/blob/master/10-%E9%83%A8%E7%BD%B2Heapster%E6%8F%92%E4%BB%B6.md
http://jimmysong.io/blogs/kubernetes-installation-on-centos/
http://jimmysong.io/blogs/kubernetes-ha-master-installation/
http://c.isme.pub/2016/11/22/docker-kubernetes/