Manage tool: Ambari+Bigtop
HDFS/YARN/MapReduce2/Tez/Hive/HBase/ZooKeeper/Spark/Zeppelin/Flink
Flink-cdc/datax/seatunnel/dolphinscheduler
Introduction
Recommend: heibaiying/BigData-Notes: 大数据入门指南 :star: (github.com)
Bigtop
Bigtop is an Apache Foundation project for Infrastructure Engineers and Data Scientists looking for comprehensive packaging, testing, and configuration of the leading open source big data components.** Bigtop supports a wide range of components/projects, including, but not limited to, Hadoop, HBase and Spark.
There are 2 ways to install bigtop:
build package from source
***Not recommend, it’s very complicate. especially in China mainland.
Prerequisite:
1 | #Jdk |
Building:
Notice: Need a non-root to compile.
1 | sudo su - hadoop |
Troubleshooting:
1 | #lacking some of jars |
bigtop Repositories
It’s a easy way to install, including ambari packages:
1 | #Clone to local repository: |
Ambari
The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
Notice: Bigtop repository has included all of ambari packages, you don’t need to build. just need to build the latest version that bigtop not included.
For installation, please follow this instructions: Installation Guide for Ambari 2.8.0 - Apache Ambari - Apache Software Foundation
Build package from source
Prerequisite:
1 | #Jdk |
Build package from source
1 | #https://cwiki.apache.org/confluence/display/AMBARI/Installation+Guide+for+Ambari+2.8.0 |
Build your yum repository:
See: bigtop Section
Installing Ambari
Performence:
| IP地址 | Role |
|---|---|
| 192.168.80.225 | NameNode ResourceManager HBase Master MySQL Zeppelin Server Grafana flume ds-master ds-api ds-alert Ambari Server Ambari Agant |
| 192.168.80.226 | SNameNode HBase Master JobHistory Server Flink History Server Spark History Server Spark Thrift Server Hive Metastore HiveServer2 WebHCat Server Datax-webui flume Ambari Agant |
| 192.168.80.227 | DataNode NodeManager Zookeeper JournalNode RegionServer ds-worker Datax worknode Ambari Agant |
| 192.168.80.228 | DataNode NodeManager Zookeeper JournalNode RegionServer ds-worker Datax worknode Ambari Agant |
| 192.168.80.229 | DataNode NodeManager Zookeeper JournalNode RegionServer ds-worker Datax worknode Ambari Metrics Collectors Ambari Agant |
HA:
| IP地址 | Role |
|---|---|
| 192.168.80.225 | NameNode ResourceManager(Single) JobHistory Server(Single) HBase Master Flink History Server Spark History Server Hive Metastore HiveServer2 WebHCat Server(Single) Zeppelin Server(Single) MySQL(Single) Grafana(Single) flume ds-master ds-api ds-alert Ambari Metrics Collectors Ambari Server Ambari Agant |
| 192.168.80.226 | SNameNode HBase Master Flink History Server Spark History Server Hive Metastore HiveServer2 ds-master Ambari Metrics Collectors flume Ambari Agant |
| 192.168.80.227 | DataNode NodeManager Zookeeper JournalNode Kafka Broker Spark Thrift Server RegionServer ds-worker Datax worknode Ambari Agant |
| 192.168.80.228 | DataNode NodeManager Zookeeper JournalNode Kafka Broker Spark Thrift Server RegionServer ds-worker Datax worknode Ambari Agant |
| 192.168.80.229 | DataNode NodeManager Zookeeper JournalNode Kafka Broker Spark Thrift Server RegionServer ds-worker Datax worknode Ambari Agant |
Vagrant Docker
Dockerfile.centos
1 | cd /works/tools/vagrant |
docker-entrypoint.sh
1 | cat docker-entrypoint.sh |
script.sh
1 | cat script.sh |
buildImages.sh
1 | cat buildImages.sh |
Push image
1 | docker login registry.zerofinance.net |
Vagrantfile
1 | cat Vagrantfile |
Vagrant start
1 | vagrant up |
Initiation
SSH Without Password
1 | #Working all machines: |
Optional: Docker CentOS
1 | #If your centos is installed on docker: |
NTP
1 | #https://www.cnblogs.com/Sungeek/p/10197345.html |
Environment variables
1 | cat /etc/profile.d/my_env.sh |
Installation
MySQL
1 | #install on 80.225 |
Ambari Server
1 | #192.168.80.225 With Root: |
Ambari Agent
1 | #Install ambari angent on all machines: |
bigtop repo
1 | #bigtop repo(192.168.80.225): |
Install Hadoop Ecosystem
1 | web portal: |
Troubleshooting
1 | 1.hive went wrong by: |
dolphinscheduler
1 | #https://dolphinscheduler.apache.org/zh-cn/docs/3.1.8/guide/installation/pseudo-cluster |
Summary
1 | Components: |
Notice: dolphinscheduler 3.1.2 seems having a bug by working with Flink-Stream, the error as follows. I have no idea to resolve it:
1 | [ERROR] 2023-09-22 09:47:30.455 +0000 - Task execute failed, due to meet an exception |
Hadoop
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Introduction: BigData-Notes/notes/Hadoop-HDFS.md at master · heibaiying/BigData-Notes (github.com)
Shell: BigData-Notes/notes/HDFS常用Shell命令.md at master · heibaiying/BigData-Notes (github.com)
HDFS: BigData-Notes/notes/Hadoop-HDFS.md at master · heibaiying/BigData-Notes (github.com)
MapReduce2: BigData-Notes/notes/Hadoop-MapReduce.md at master · heibaiying/BigData-Notes (github.com)
YARN: BigData-Notes/notes/Hadoop-YARN.md at master · heibaiying/BigData-Notes (github.com)
JavaAPI: BigData-Notes/notes/HDFS-Java-API.md at master · heibaiying/BigData-Notes (github.com)
Windows Client
1 | git clone https://gitcode.net/mirrors/cdarlint/winutils |
Configuation
Put core-site.xml and hdfs-site.xml to resources folder of your java project:
core-site.xml
1 | <configuration xmlns:xi="http://www.w3.org/2001/XInclude"> |
hdfs-site.xml
1 | <configuration xmlns:xi="http://www.w3.org/2001/XInclude"> |
Hive
The Apache Hive ™ is a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale and facilitates reading, writing, and managing petabytes of data residing in distributed storage using SQL.
internal table
If table has beed deleted, all data will be delete accordingly, including meta data and file data.
1 | #https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML |
external table
If table has beed deleted, just meta data will be deleted. once you create table again, the data will be restored, no need load again.
1 | #sudo -u hdfs hadoop fs -chown -R hive:hive /works/test/ |
Partition
1 | CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE; |
Insert Directory
1 | #selects all rows from partition ds=2008-08-15 of the invites table into an HDFS directory. The result data is in files (depending on the number of mappers) in that directory. |
Insert Table
1 | CREATE TABLE events (foo INT, bar STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE; |
Date Type
Hive 数据类型 | Hive 教程 (hadoopdoc.com)
A complex demo for data type.
1 | CREATE TABLE students( |
STRUCT
1 | CREATE TABLE IF NOT EXISTS person_1 (id int,info struct<name:string,country:string>) |
ARRAY
1 | CREATE TABLE IF NOT EXISTS array_1 (id int,name array<STRING>) |
MAP
1 | CREATE TABLE IF NOT EXISTS map_1 (id int,name map<STRING,STRING>) |
UINON
1 | //创建DUAL表,插入一条记录,用于生成数据 |
ES
1 | docker pull registry.zerofinance.net/library/elasticsearch:7.6.2 |
Flink
BigData-Notes/notes/Flink核心概念综述.md at master · heibaiying/BigData-Notes (github.com)
Flink SQL
史上最全干货!Flink SQL 成神之路(全文 18 万字、138 个案例、42 张图) | antigeneral’s blog (yangyichao-mango.github.io)
Deployment Modes
See this Overview to understand: deployment-modes
Standalone
Session Mode
1 | # we assume to be in the root directory of the unzipped Flink distribution |
In step (1), we’ve started 2 processes: A JVM for the JobManager, and a JVM for the TaskManager. The JobManager is serving the web interface accessible at localhost:8081. In step (3), we are starting a Flink Client (a short-lived JVM process) that submits an application to the JobManager.
1 | #Troubleshooting: 8081 can be visited only for localhost |
Application Mode
1 | To start a Flink JobManager with an embedded application, we use the bin/standalone-job.sh script. We demonstrate this mode by locally starting the TopSpeedWindowing.jar example, running on a single TaskManager. |
YARN
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/resource-providers/yarn/
Session Mode
starting-a-flink-session-on-yarn
1 | export HADOOP_CLASSPATH=`hadoop classpath` |
Congratulations! You have successfully run a Flink application by deploying Flink on YARN.
We describe deployment with the Session Mode in the Getting Started guide at the top of the page.
The Session Mode has two operation modes:
- attached mode (default): The
yarn-session.shclient submits the Flink cluster to YARN, but the client keeps running, tracking the state of the cluster. If the cluster fails, the client will show the error. If the client gets terminated, it will signal the cluster to shut down as well. - detached mode (
-dor--detached): Theyarn-session.shclient submits the Flink cluster to YARN, then the client returns. Another invocation of the client, or YARN tools is needed to stop the Flink cluster.
The session mode will create a hidden YARN properties file in /tmp/.yarn-properties-<username>, which will be picked up for cluster discovery by the command line interface when submitting a job.
You can also manually specify the target YARN cluster in the command line interface when submitting a Flink job. Here’s an example:
1 | ./bin/flink run -t yarn-session \ |
You can re-attach to a YARN session using the following command:
1 | ./bin/yarn-session.sh -id application_XXXX_YY |
Besides passing configuration via the conf/flink-conf.yaml file, you can also pass any configuration at submission time to the ./bin/yarn-session.sh client using -Dkey=value arguments.
The YARN session client also has a few “shortcut arguments” for commonly used settings. They can be listed with ./bin/yarn-session.sh -h.
Application Mode
1 | Application Mode will launch a Flink cluster on YARN, where the main() method of the application jar gets executed on the JobManager in YARN. The cluster will shut down as soon as the application has finished. You can manually stop the cluster using yarn application -kill <ApplicationId> or by cancelling the Flink job. |
Native_kubernetes
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/filesystems/oss/
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/ha/overview/
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/ha/kubernetes_ha/
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/config/#kubernetes
K8s On Session
Creating service account:
1 | #https://blog.csdn.net/yy8623977/article/details/124989262 |
Building required jars into docker image(Or mount a folder from NAS).
Dockerfile:
1 | FROM apache/flink:1.17.2-scala_2.12 |
ll ./lib-1.17/
1 | -rw-r--r-- 1 root root 266420 Jun 15 2023 flink-connector-jdbc-3.1.1-1.17.jar |
Build and push to registry:
1 | docker build -t registry.zerofinance.net/library/flink:1.17.2 . |
Starting flink job manager:
1 | #For 1.15.x 1.16.x |
Enable cluster-rest ingress:
flink-cluster-rest-ingress.yml:
1 | apiVersion: extensions/v1beta1 |
Submits a new job:
1 | bin/flink run -m flink-rest-test.zerofinance.net examples/batch/WordCount.jar |
Or:
1 | bin/flink run \ |
Destroy a existing cluster:
1 | kubectl -n flink-test delete deploy flink-cluster |
K8s On Application
1 | #Starting: |
Sql Client
Flink 使用之 SQL Client - 简书 (jianshu.com)
Standalone
1 | start-cluster.sh |
On yarn Session
Configuring SQL Client for session mode | CDP Private Cloud (cloudera.com)
1 | #Start a yarn session |
Connectors
Flink doesn’t include any connector depended libraries, you need to download them manually.
1 | #kafka Connector: |
Restore job
1 | #https://mp.weixin.qq.com/s/srUyvNr7KX1PSOaG1d8qdQ?poc_token=HGNqmWWjWqONGGyPVzyzKzDhIsyauXyJ8kOW8Bfl |
Optimize
1 | SET parallelism.default=1; |
StreamPark
Recommend.
Apache StreamPark (incubating) | Apache StreamPark (incubating)
Installation
Standalone
1 | #https://streampark.apache.org/docs/user-guide/deployment |
Noticed: In order to launch kubernetes flink environment, you must have config file of kubectl(~/.kube/config) installed.
Docker
Dockerfile
raw.githubusercontent.com/apache/incubator-streampark/v2.1.2/deploy/docker/Dockerfile
1 | FROM alpine:3.16 as deps-stage |
Building
1 | DOCKER_BUILDKIT=0 docker build -t "registry.zerofinance.net/flink/streampark:2.1.2" . |
Creating docker
1 | docker run -d --name "streampark" \ |
Start streampark instance
1 | docker exec -it streampark bash |
K8s
1 | apiVersion: apps/v1 |
Configuration
System Setting
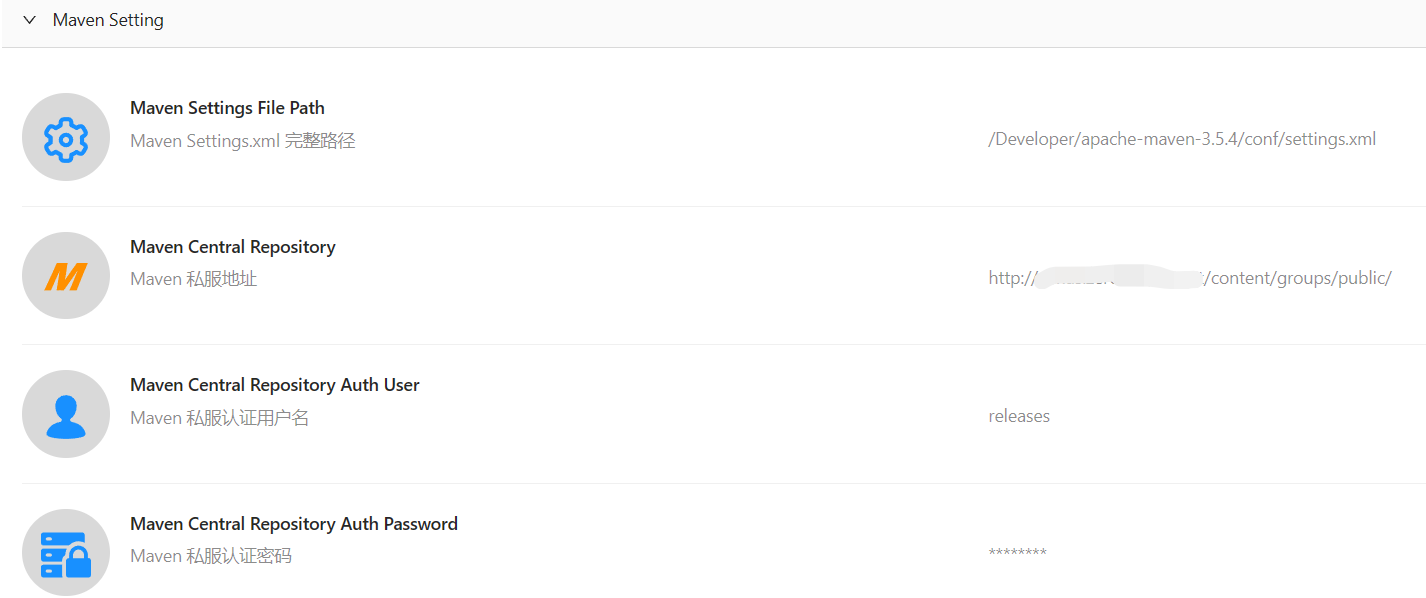
First, you need creating a registry project named “flink” from menu: “Project Quotas”.
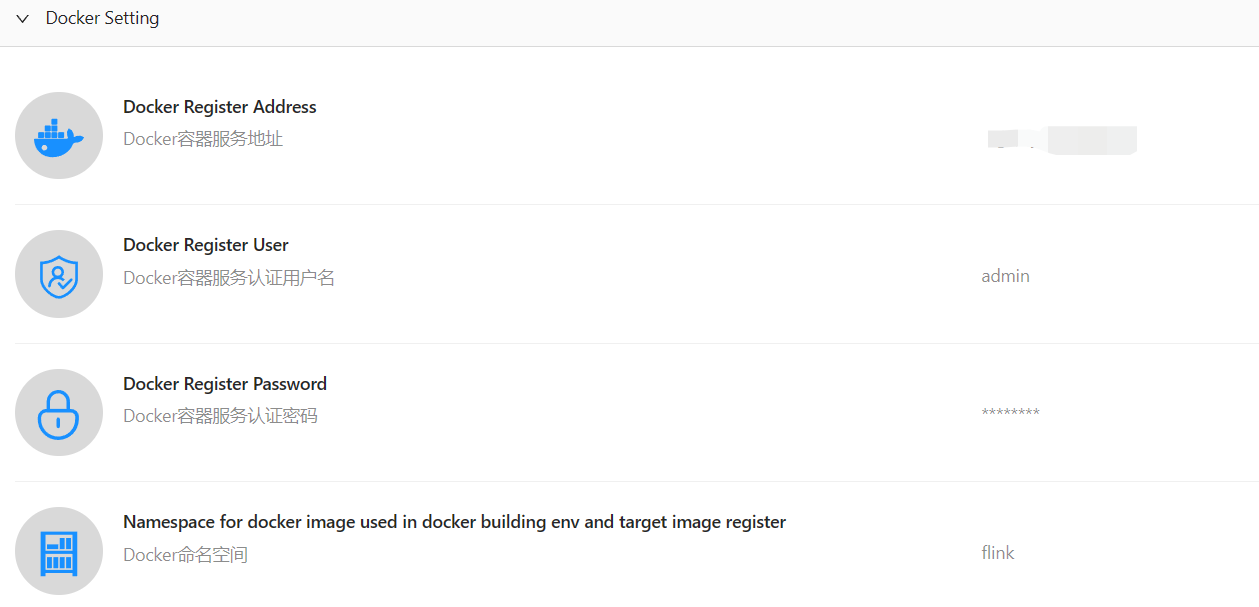
Flink Cluster
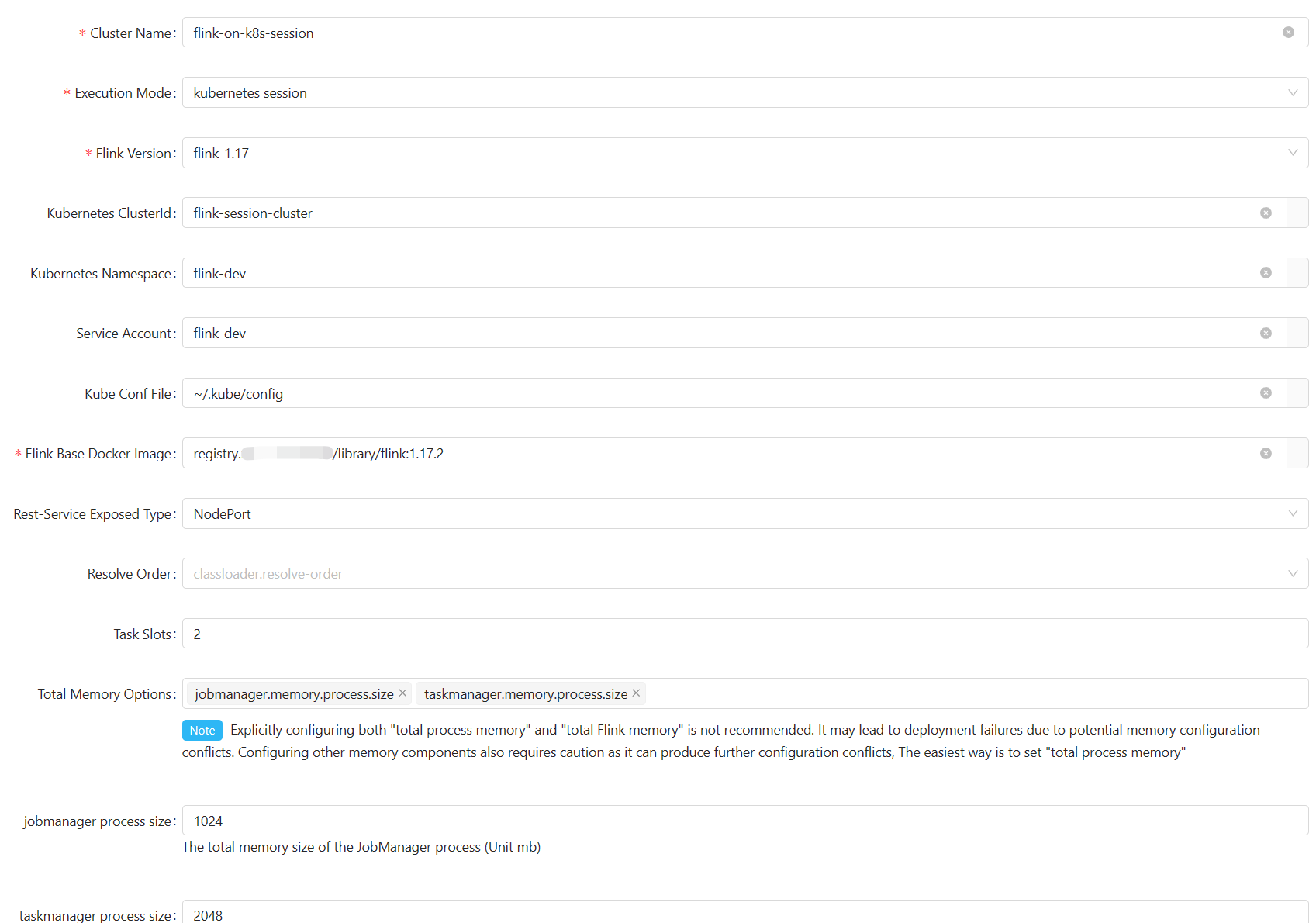
Flink Home

Application
application sql Job
(Recommend)
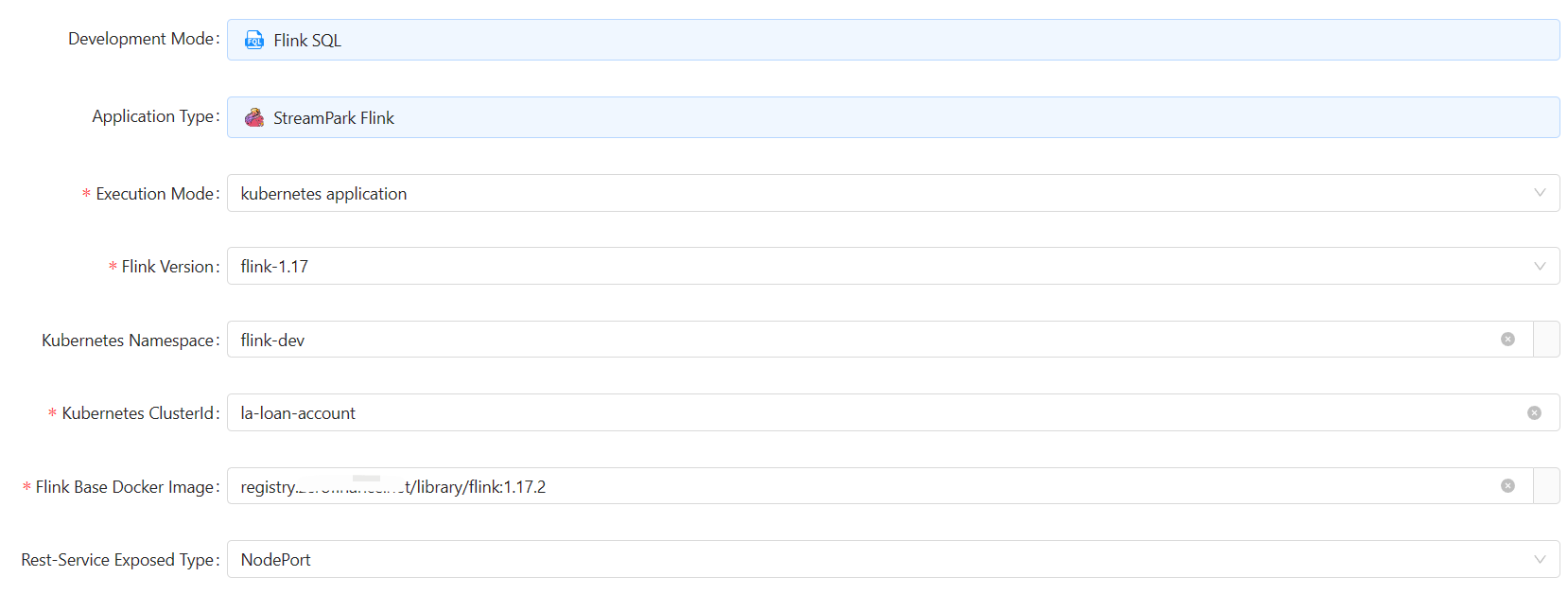
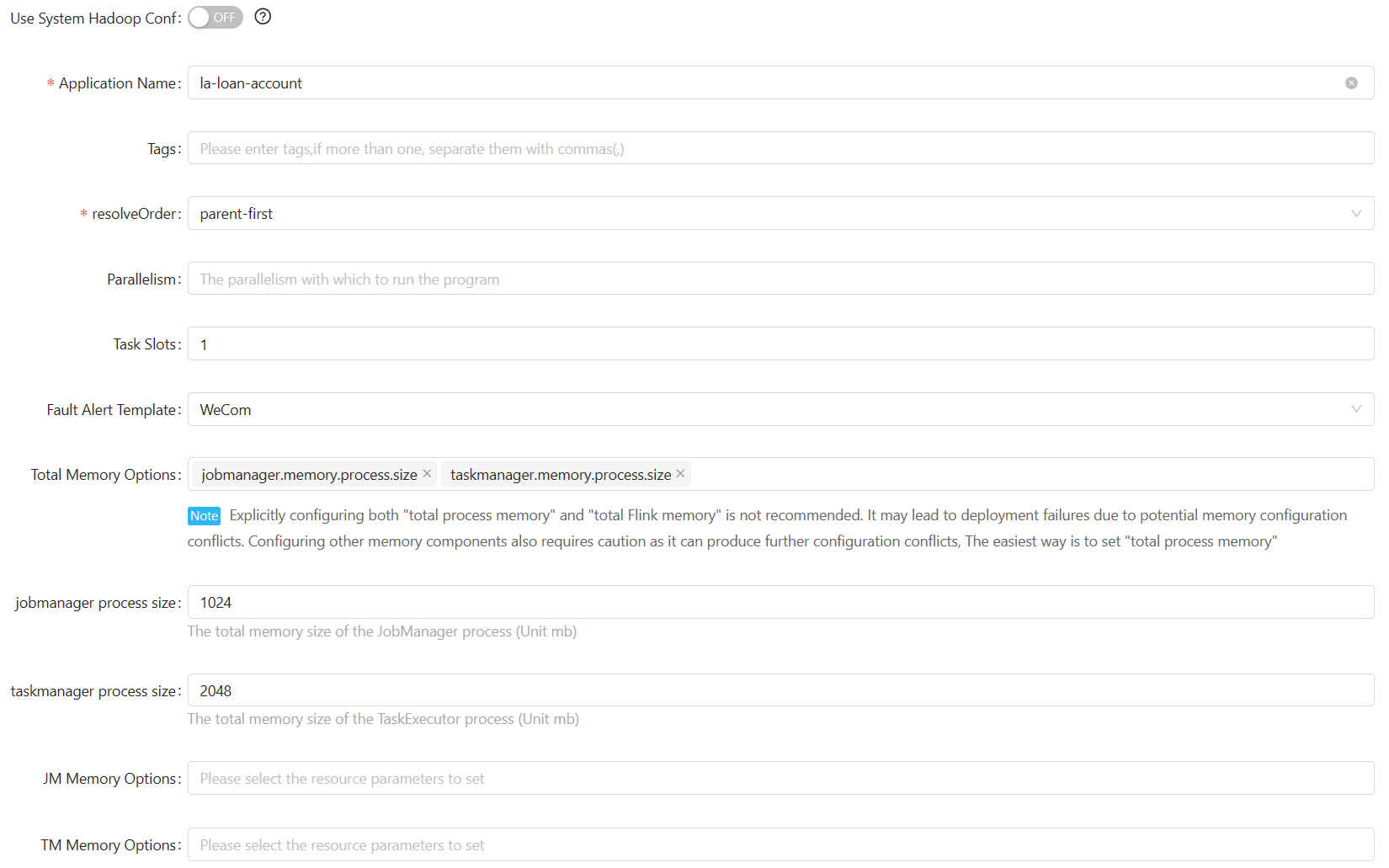
session sql job
You have to start the session instance from “Settings—>Flink Cluster”
application jar job
Create Project first:

Create a new jar job:
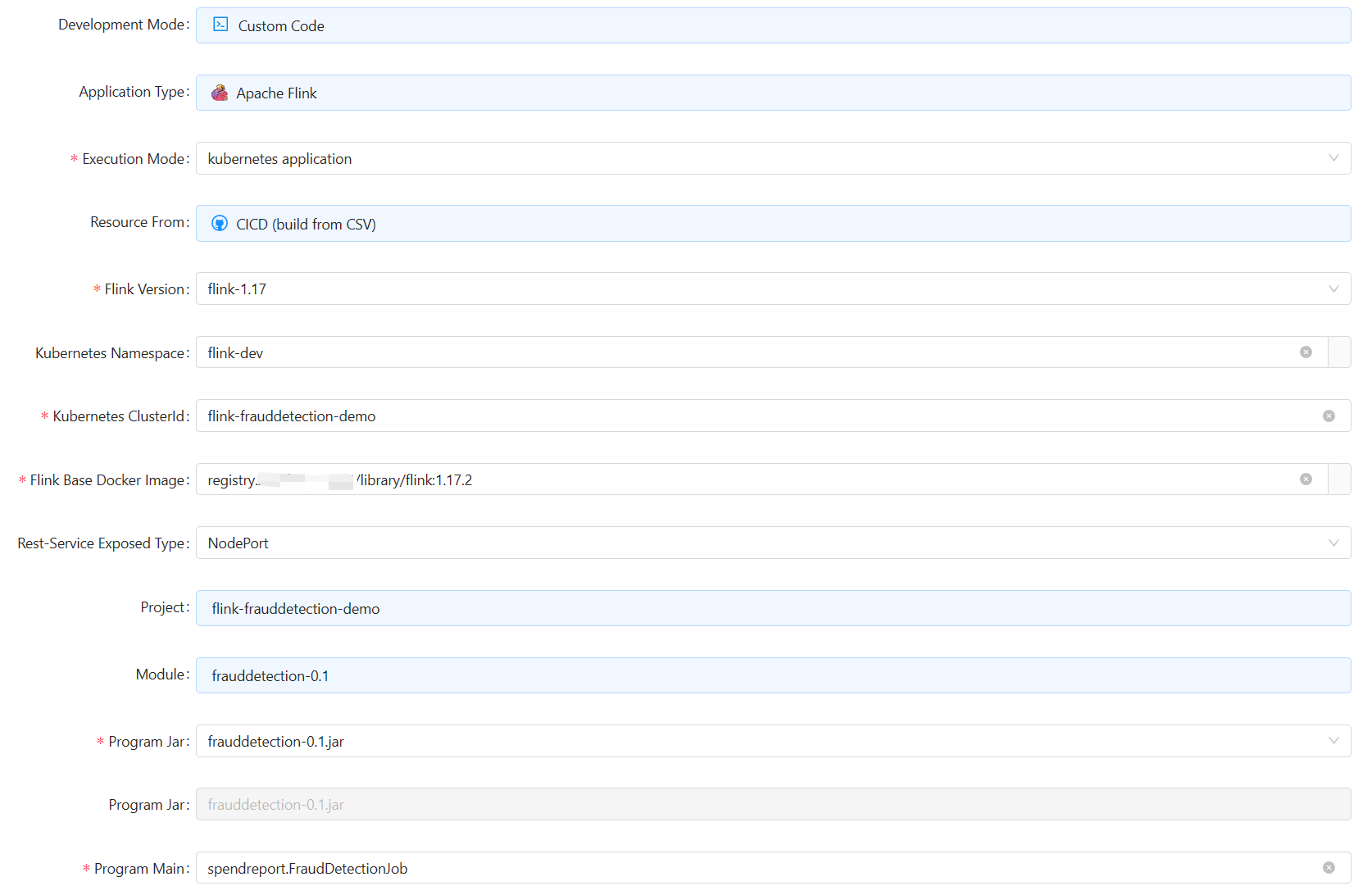
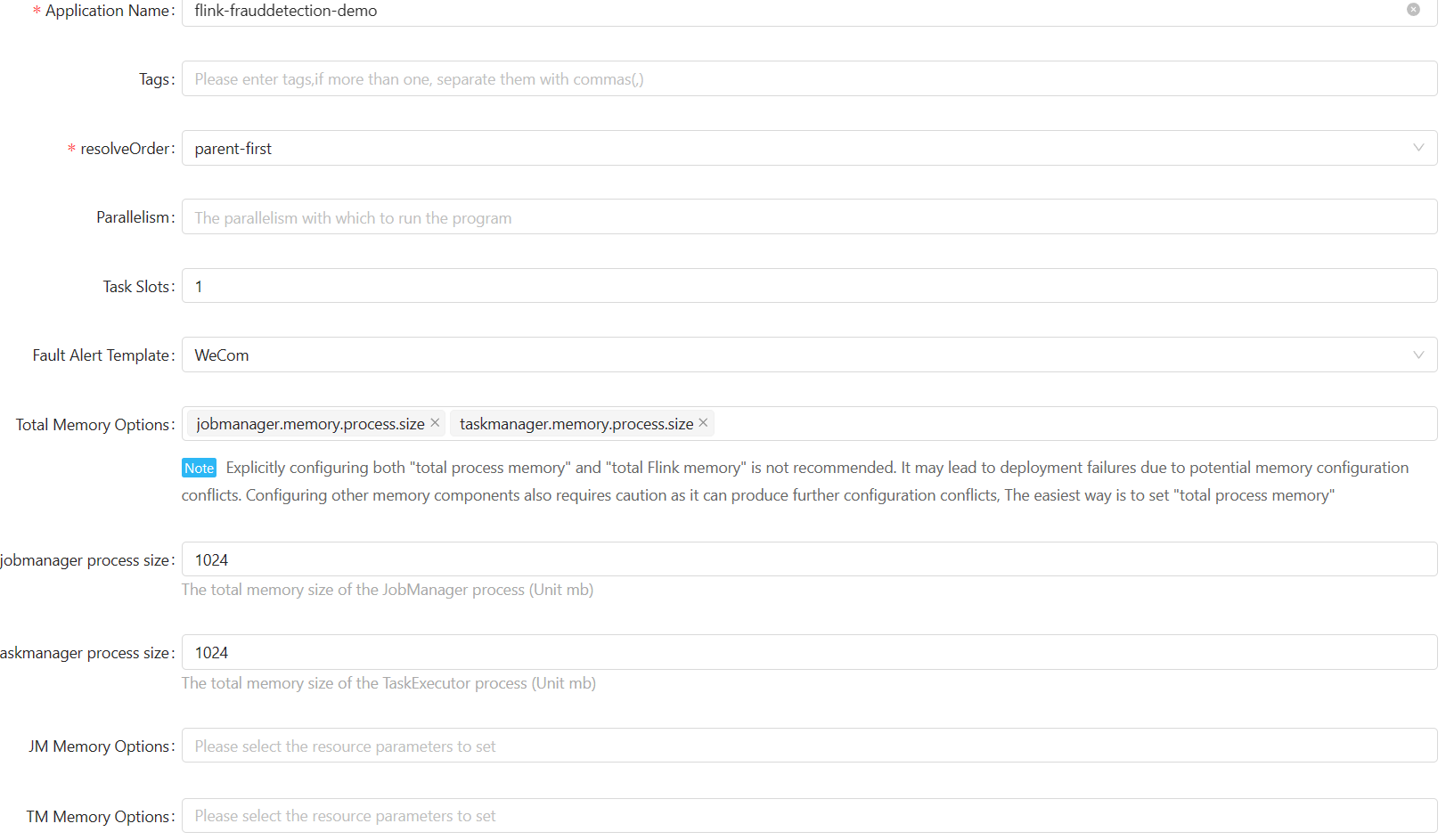
Pod template
Pod Template
In order to collect logs to Loki:
1 | apiVersion: v1 |
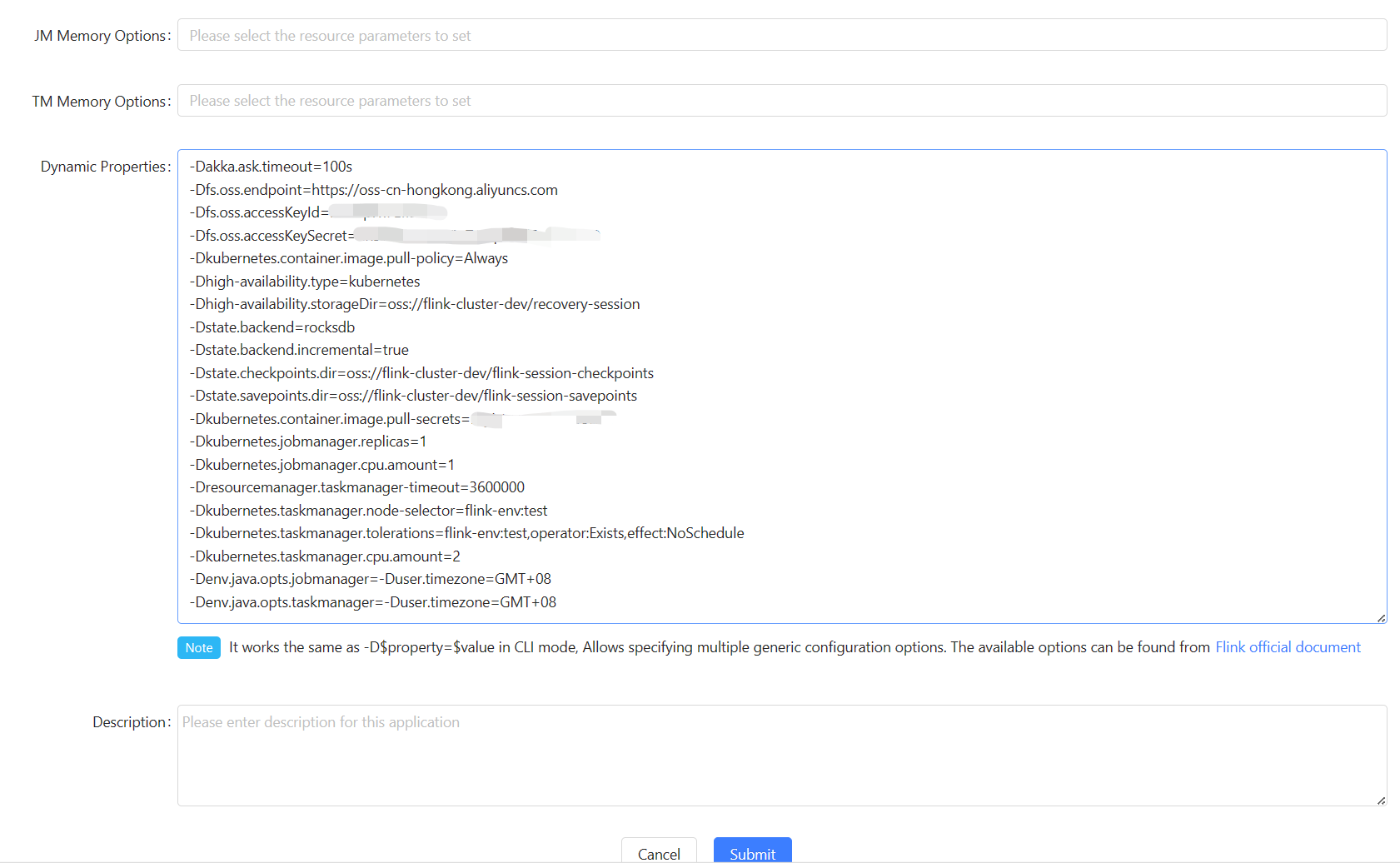
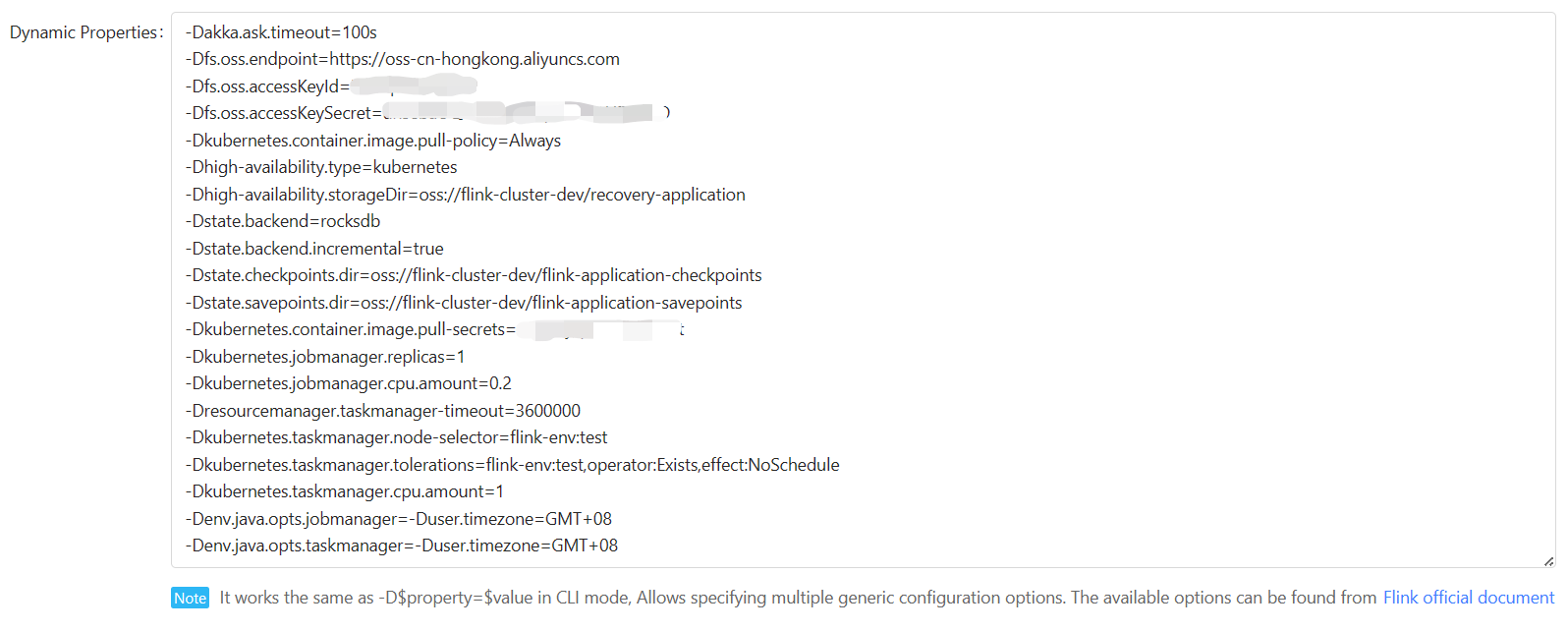
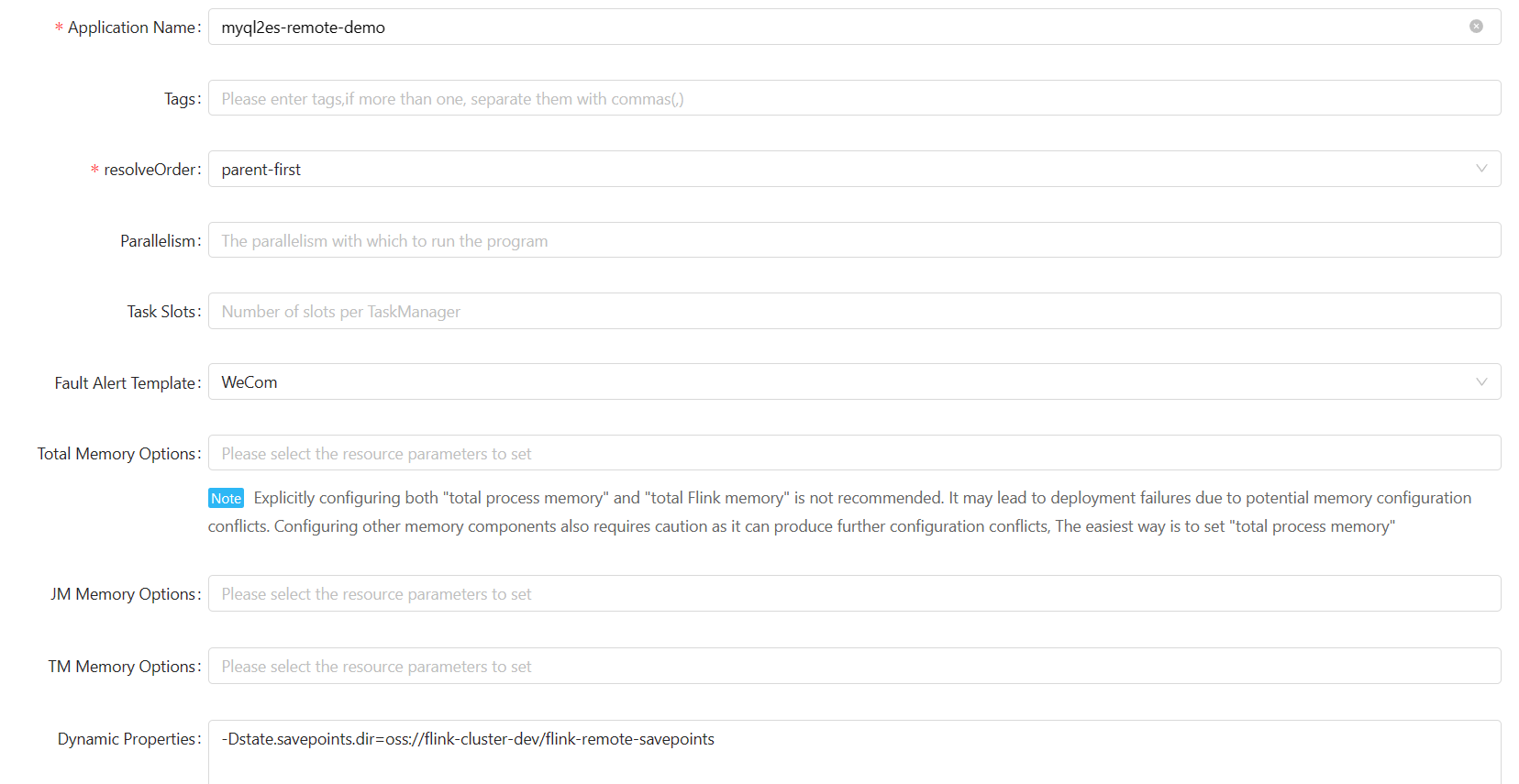
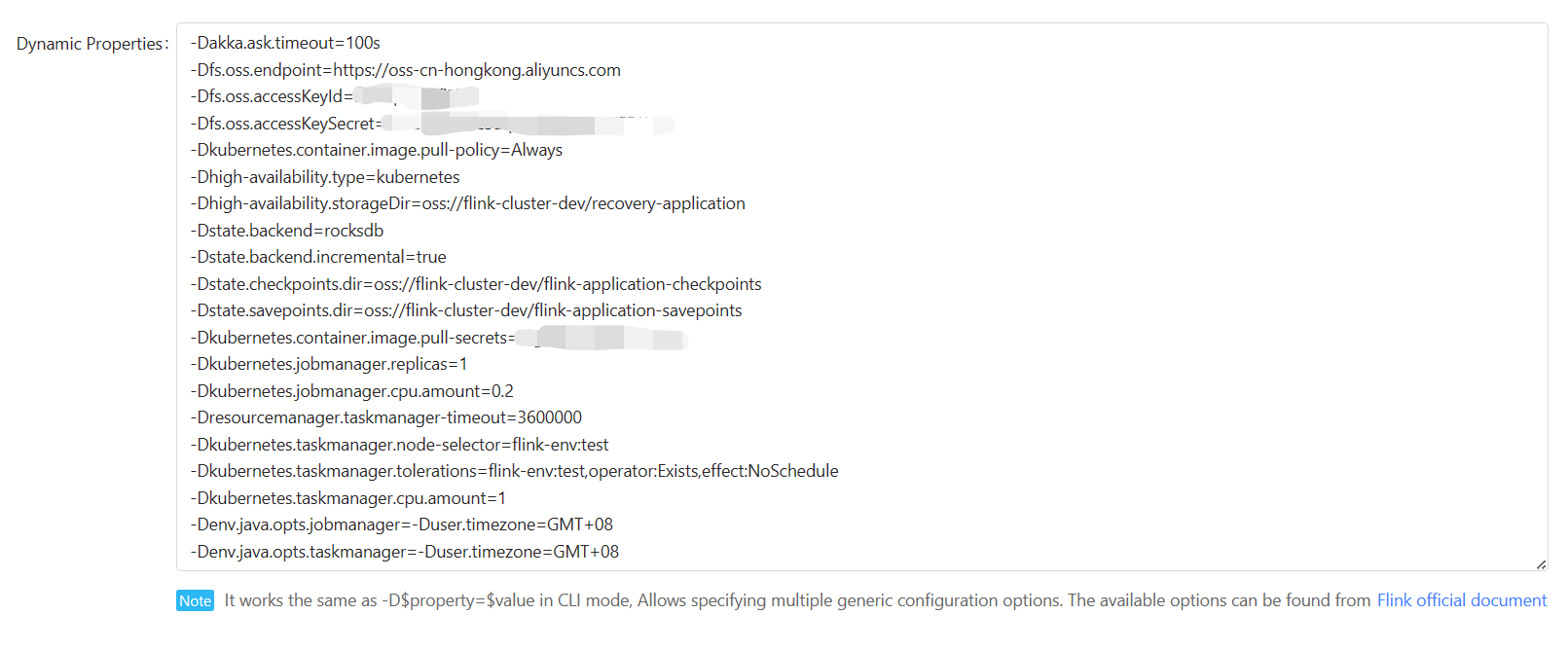
Dynamic Properties
You can simplify “Dynamic Properties”:
1 | -Dakka.ask.timeout=100s |
Clean all Jobs
1 | k -n flink-dev delete deploy myql2es-deploy-demo |
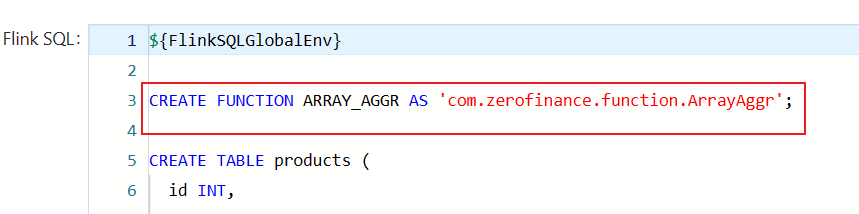
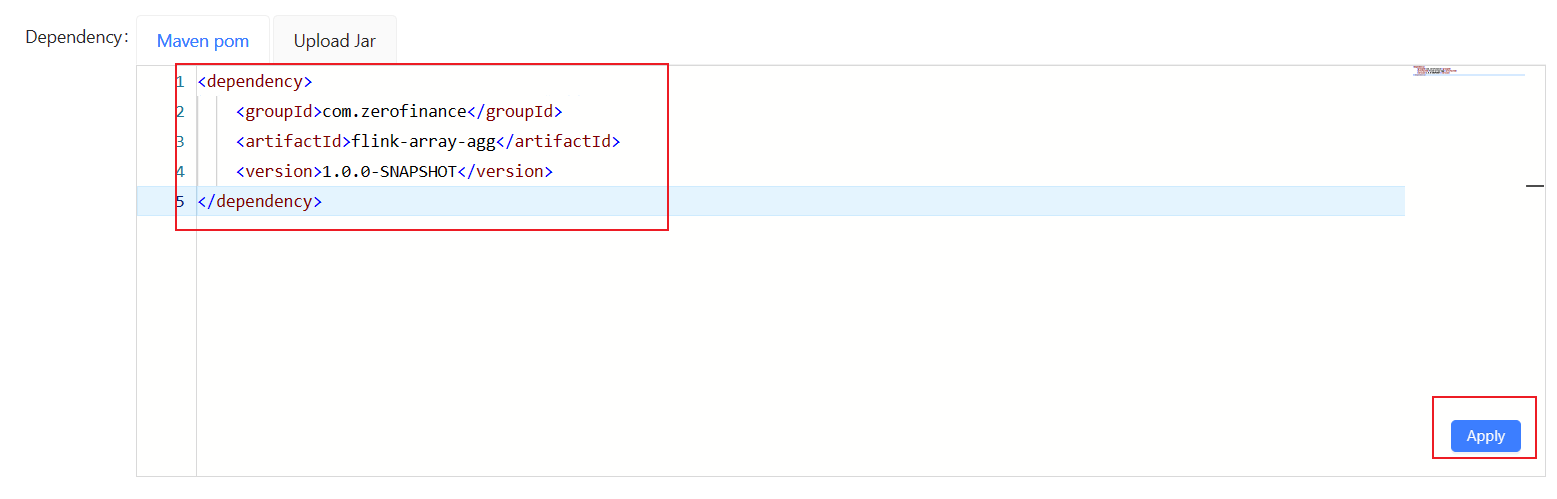
UDF
Create a project first:
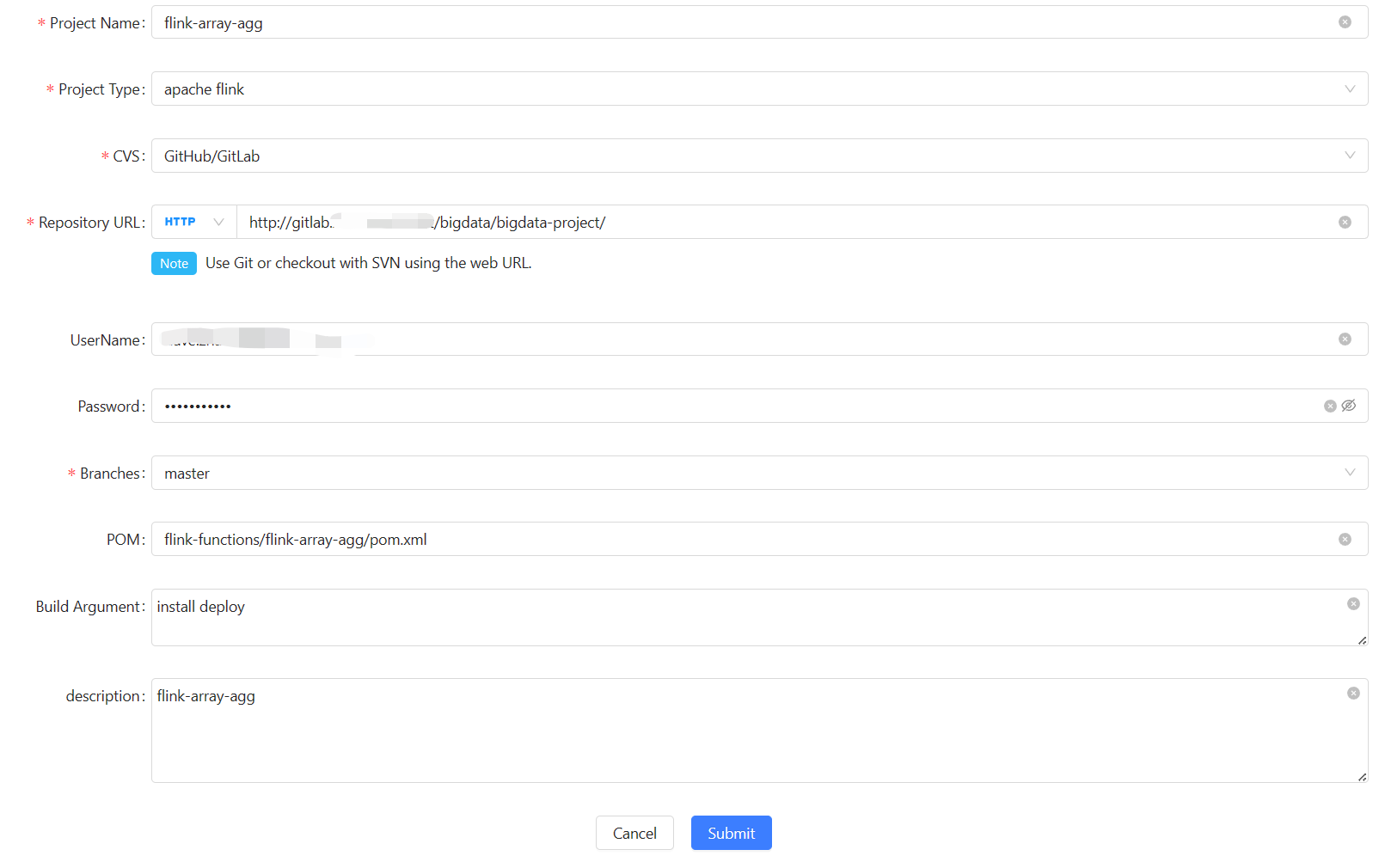

Adding dependency pom in a job:
Dinky
A alternative Flink stream platform, like StreamPark. But I recommend using StreamPark strongly.
http://www.dlink.top/docs/0.7/get_started/docker_deploy
http://www.dlink.top/docs/0.7/deploy_guide/build
Prerequisite: dinky.sql
1 | mysql -uroot -p |
Linux Install
For 1.0.0 version:
1 | #http://www.dinky.org.cn/docs/next/deploy_guide/normal_deploy |
Docker
For 1.0.0 version:
1 | FROM openjdk:8u342-oracle as build-stage |
All jars in flink1.17-lib:
1 | ll build/ |
Build and push to registry:
1 | docker build --build-arg FLINK_BIG_VERSION=1.17 --build-arg DINKY_VERSION=1.17-1.0.0-rc4 -t "registry.zerofinance.net/flink/dinky-flink:1.17-1.0.0-rc4" . |
flink-dinky-template.yml:
1 | apiVersion: apps/v1 |
On Application
Must build your own image:
DinkyFlinkDockerfile(1.0.0):
1 | # 用来构建dinky环境 |
All jars in dinky-lib:
1 | ll dinky-lib/ |
Build and push to registry:
1 | docker build -t registry.zerofinance.net/flink/dinky-flink-application:1.17.2-1.0.0-rc4 . -f DinkyFlinkDockerfile |
“提交FlinkSQL的jar文件路径”为打包到镜像registry.zerofinance.net/flink/dinky-flink-application:1.17.2-1.0.0-rc4中的路径,而不是dinky中的路径。
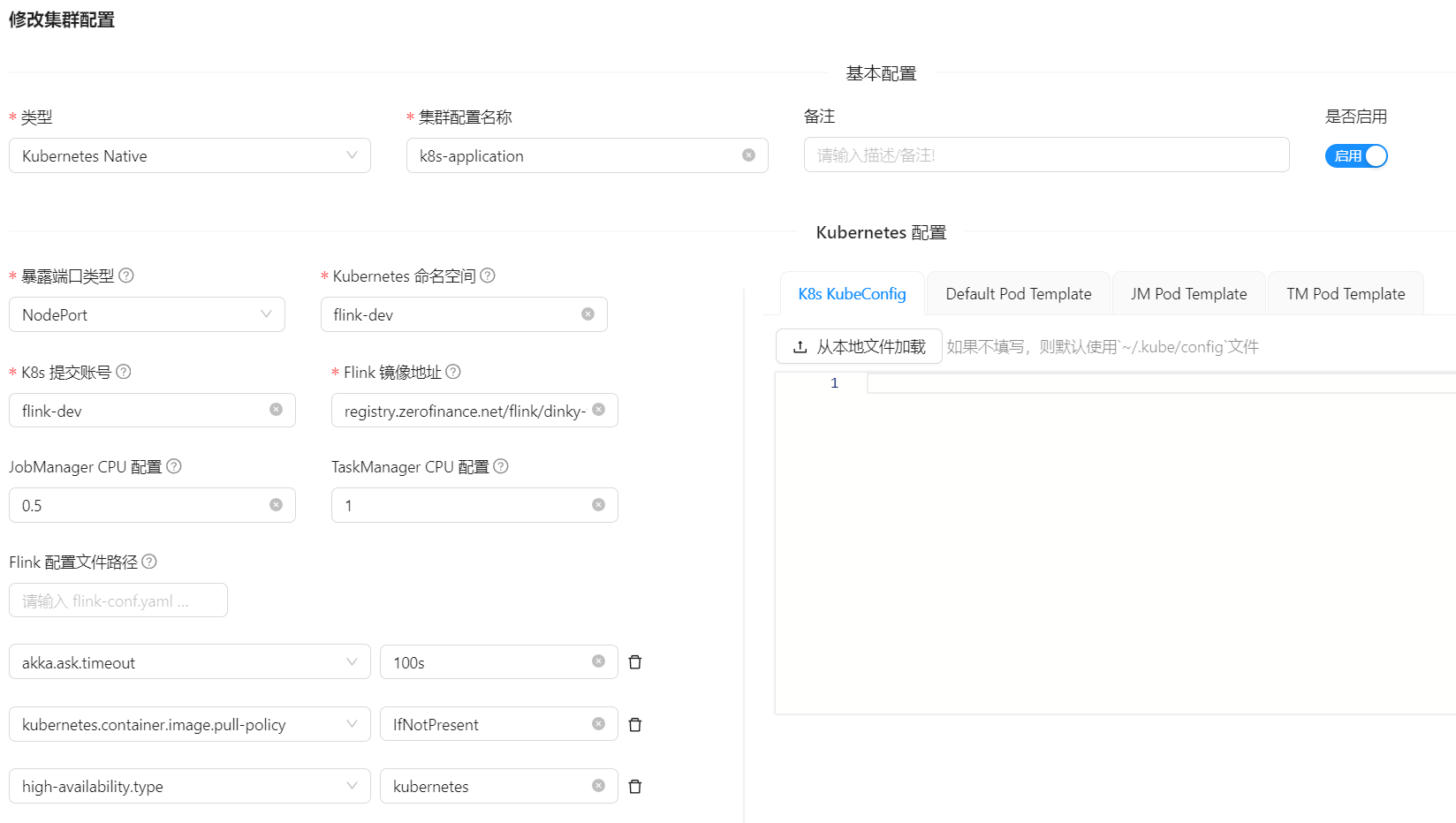
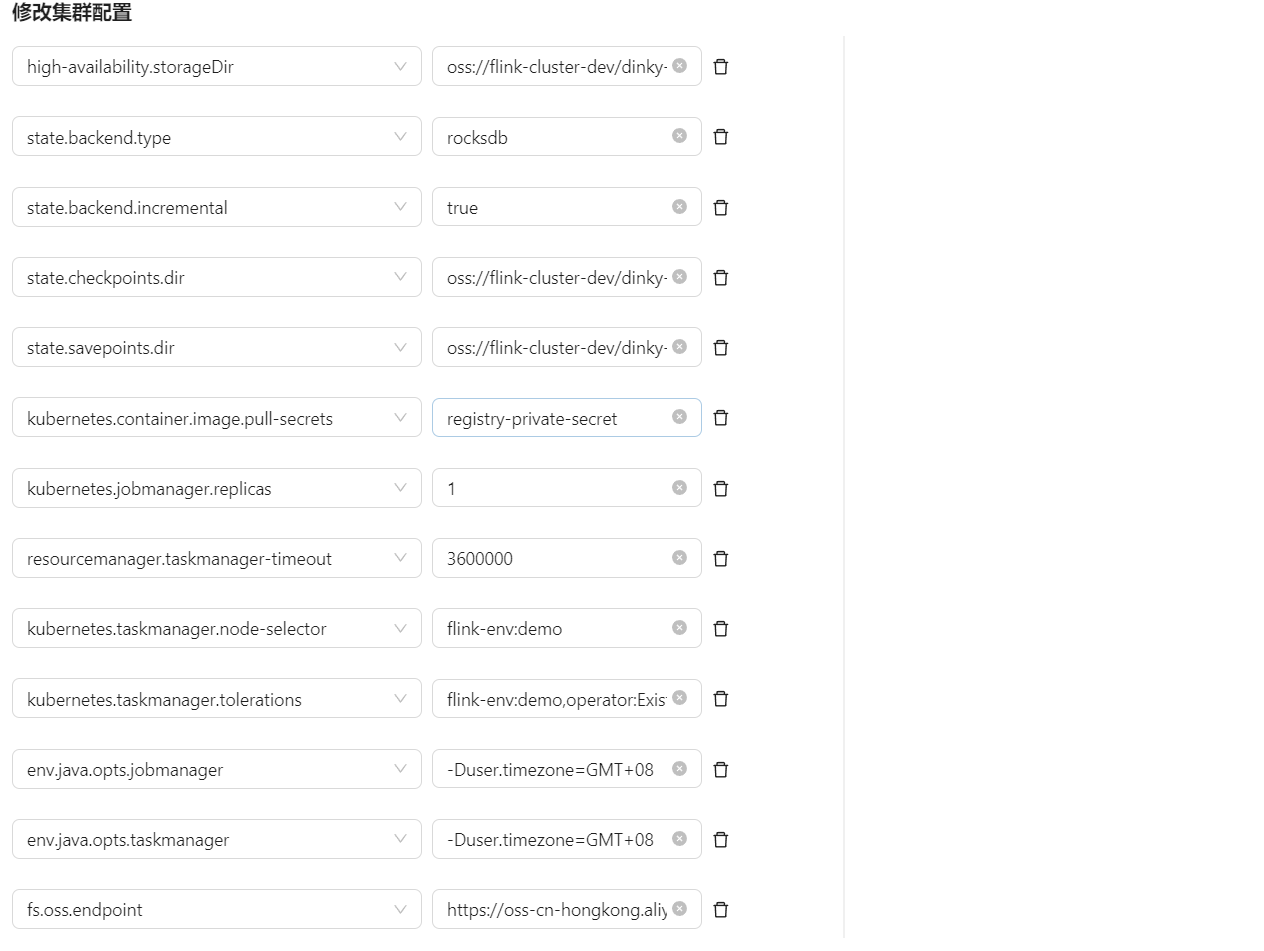
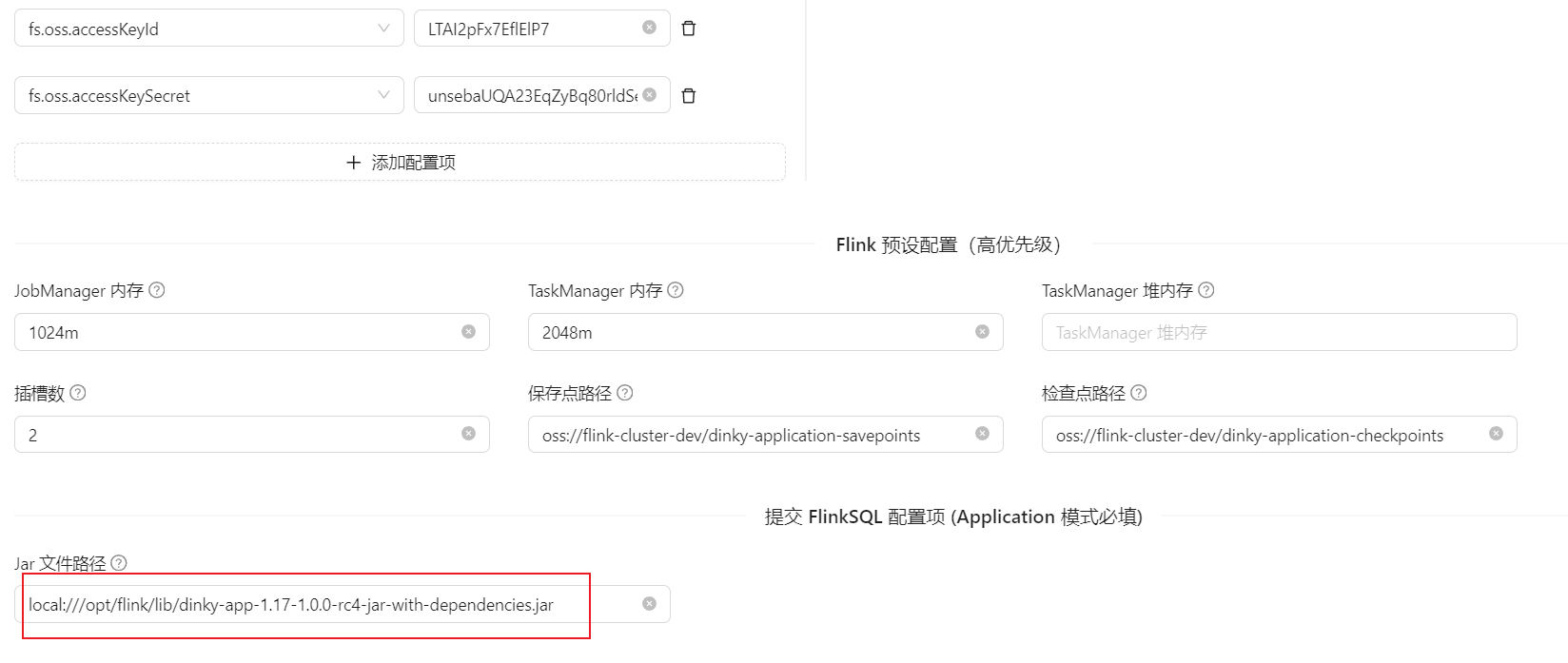
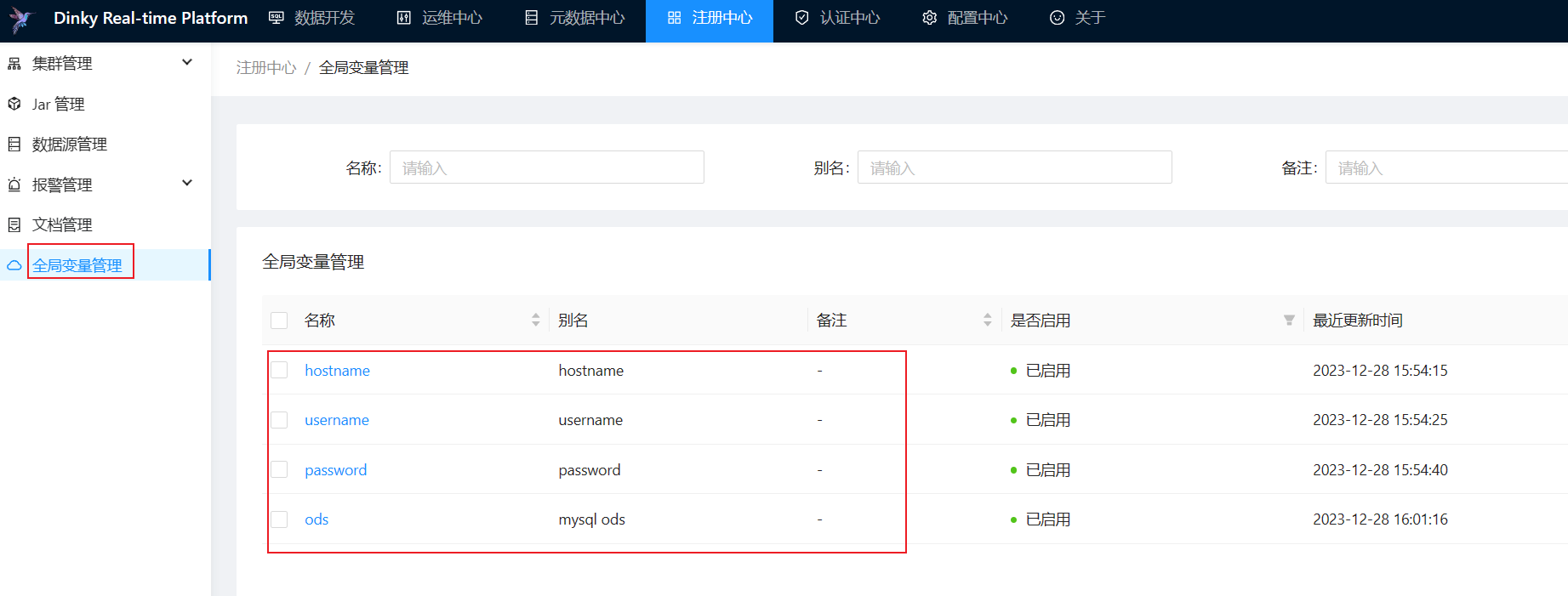
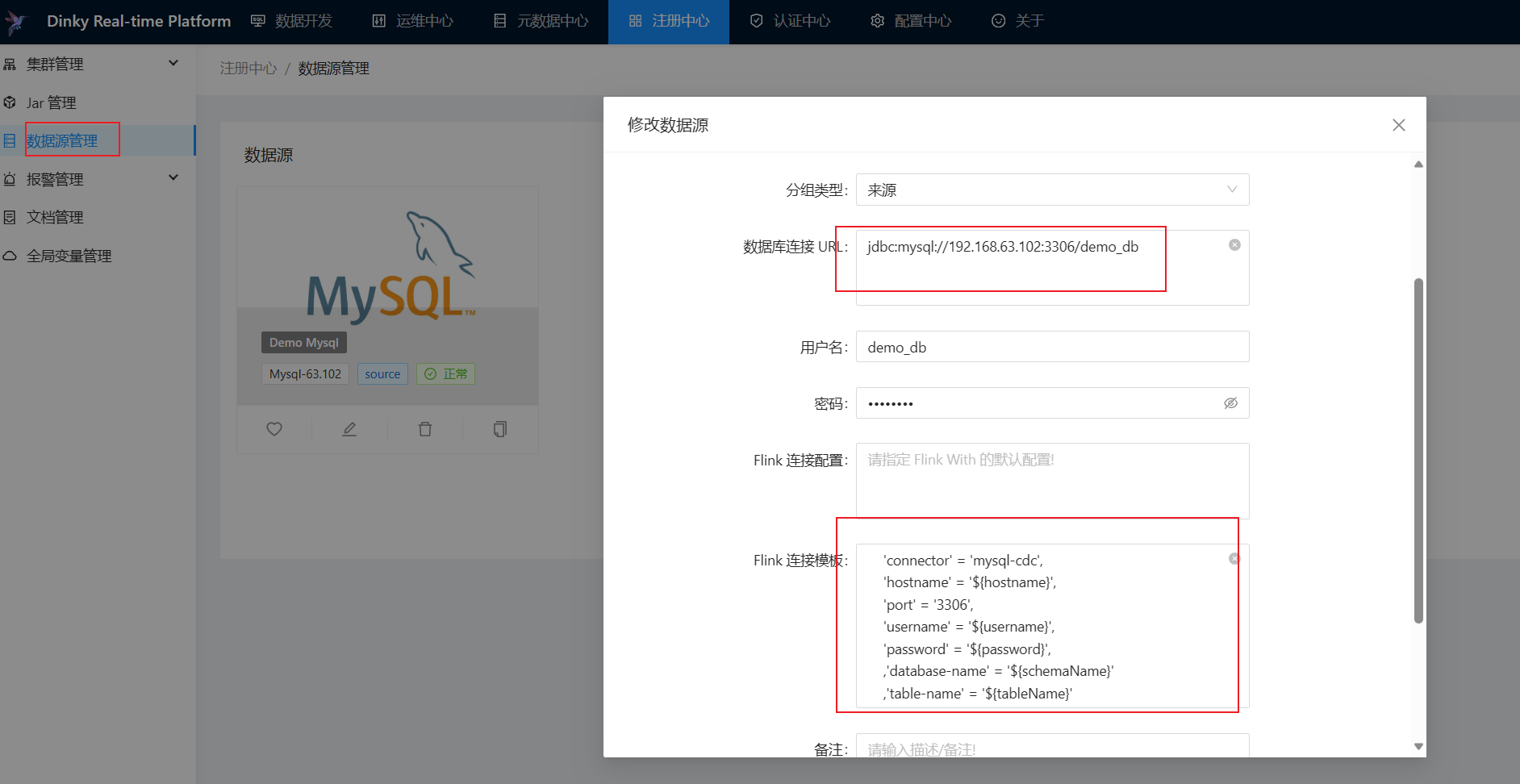
DataSource
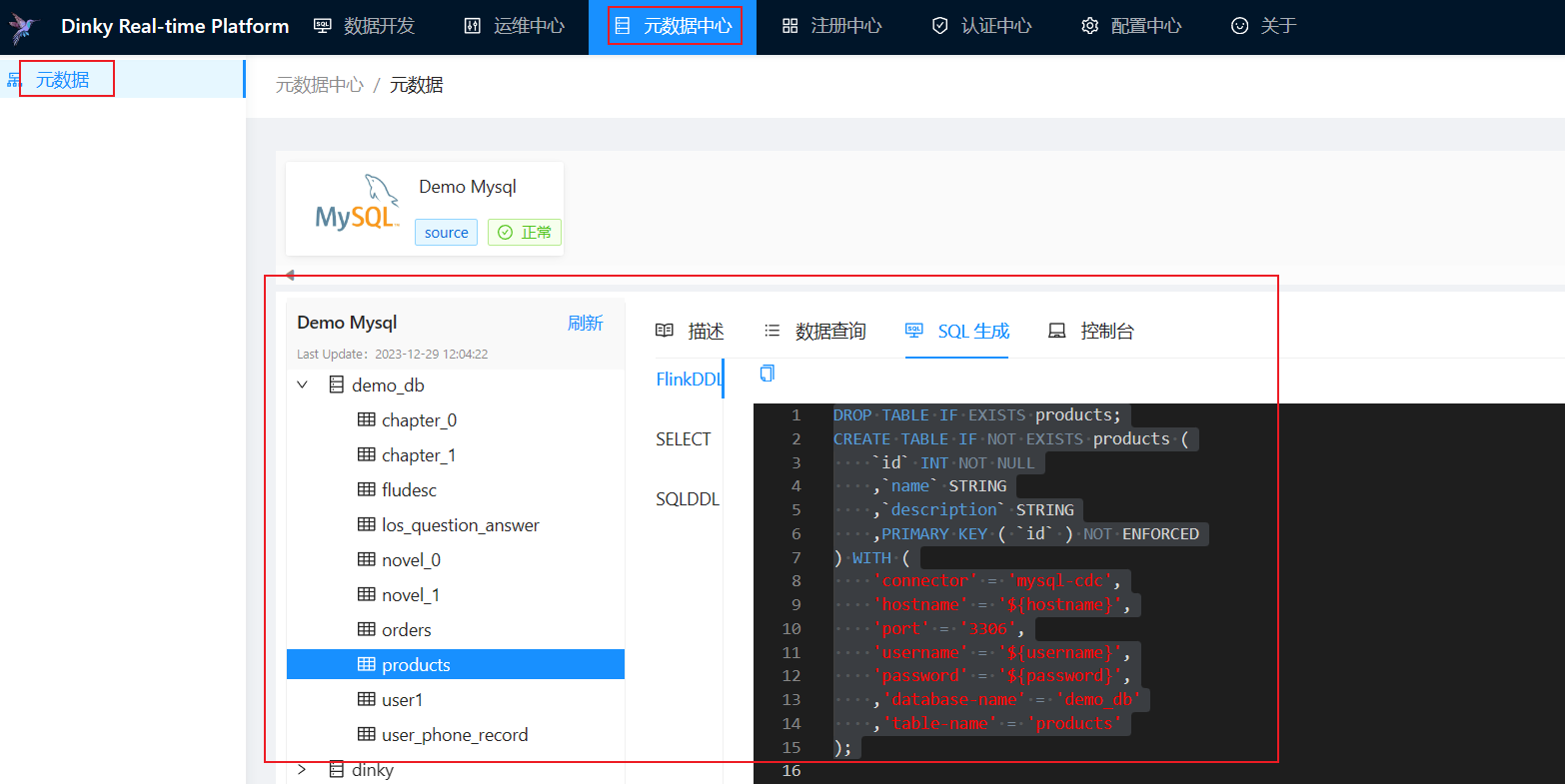
User-defined Functions
User-defined Functions | Apache Flink
User-defined functions (UDFs) are extension points to call frequently used logic or custom logic that cannot be expressed otherwise in queries.
User-defined functions can be implemented in a JVM language (such as Java or Scala) or Python. An implementer can use arbitrary third party libraries within a UDF. This page will focus on JVM-based languages, please refer to the PyFlink documentation for details on writing general and vectorized UDFs in Python.
1 | #https://yangyichao-mango.github.io/2021/11/15/wechat-blog/01_%E5%A4%A7%E6%95%B0%E6%8D%AE/01_%E6%95%B0%E6%8D%AE%E4%BB%93%E5%BA%93/01_%E5%AE%9E%E6%97%B6%E6%95%B0%E4%BB%93/02_%E6%95%B0%E6%8D%AE%E5%86%85%E5%AE%B9%E5%BB%BA%E8%AE%BE/03_one-engine/01_%E8%AE%A1%E7%AE%97%E5%BC%95%E6%93%8E/01_flink/01_flink-sql/20_%E5%8F%B2%E4%B8%8A%E6%9C%80%E5%85%A8%E5%B9%B2%E8%B4%A7%EF%BC%81FlinkSQL%E6%88%90%E7%A5%9E%E4%B9%8B%E8%B7%AF%EF%BC%88%E5%85%A8%E6%96%876%E4%B8%87%E5%AD%97%E3%80%81110%E4%B8%AA%E7%9F%A5%E8%AF%86%E7%82%B9%E3%80%81160%E5%BC%A0%E5%9B%BE%EF%BC%89/ |
Hive Catalog
1 | #https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/connectors/table/hive/hive_catalog/ |
Flink Streaming Platform Web
Prerequisite:
1 | #https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/deploy.md |
config/application.properties:
1 | ####jdbc信息 |
Build docker image:
1 | FROM centos:7 |
build and push to registry:
1 | docker build -t registry.zerofinance.net/library/flink-streaming-platform-web:1.16.2 . -f Dockerfile.web |
Starting a new instance:
1 | docker run -d --name flink-streaming-platform-web --restart=always \ |
On K8s:
flink-streaming-platform-web.yml:
1 | apiVersion: v1 |
Or:
1 | vim conf/application.properties |
Settings
Job

Flink SQL CDC
基于 Flink SQL CDC的实时数据同步方案 (dreamwu.com)
docs/sql_demo/demo_6.md · 朱慧培/flink-streaming-platform-web - Gitee.com
Overview — CDC Connectors for Apache Flink® documentation (ververica.github.io)
Enable mysql bin-log function:
1 | #temporary password: |
MySQL ON Docker
1 | ES: |
1 | > sudo su - hadoop |
The connector named kafka doesn’t support flink-sql-cdc, using ‘upset-kafka’ instead.
The error as blow:
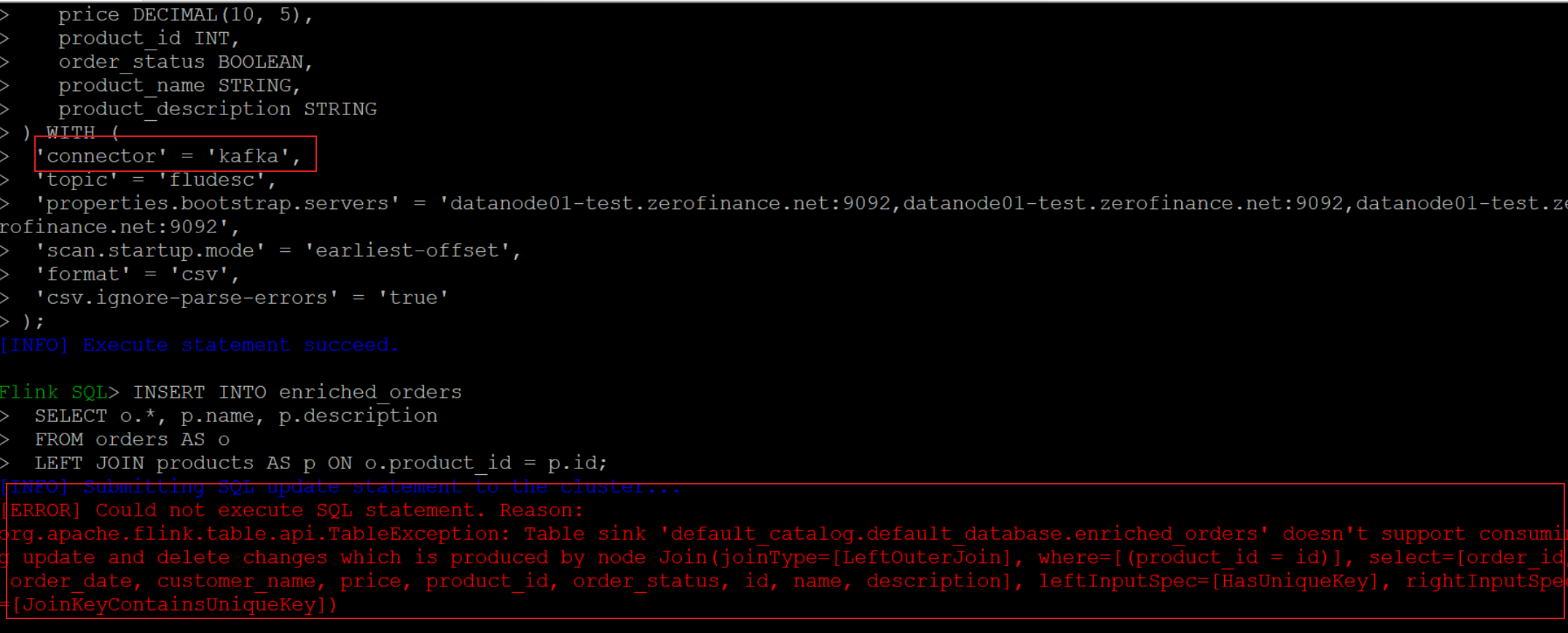
Demo
kafka to mysql Demo
This demo illustrate how to sink data from Kafka to MySQL:
1 | #https://www.jianshu.com/p/266449b9a0f4 |
kafka to hdfs Demo
1 | > sudo su - hadoop |
Mysql to hdfs Demo
1 | > sudo su - hadoop |
Mysql to ES Demo
ONE TO ONE:
1 | > sudo su - hadoop |
ONE TO MANY
UDF:
#https://www.decodable.co/blog/array-aggregation-with-flink-sql-data-streaming
ArrayAccumulator:
1 | package com.zerofinance.function; |
ArrayAggr:
1 | package com.zerofinance.function; |
1 | CREATE FUNCTION ARRAY_AGGR AS 'com.zerofinance.function.ArrayAggr'; |
Another way is put sub data to a single string filed:
1 | CREATE TABLE enriched_orders ( |
Window Aggregation
TUMBLE
Windowing TVF
1 | TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ]) |
data: is a table parameter that can be any relation with a time attribute column.timecol: is a column descriptor indicating which time attributes column of data should be mapped to tumbling windows.size: is a duration specifying the width of the tumbling windows.offset: is an optional parameter to specify the offset which window start would be shifted by.
1 | #简单且常见的分维度分钟级别同时在线用户数、总销售额 |
Group Window Aggregation
Deprecated: Group Window Aggregation, supported both batch and streaming.
1 | > sudo su - hadoop |
HOP
Windowing TVF
1 | HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ]) |
data: is a table parameter that can be any relation with an time attribute column.timecol: is a column descriptor indicating which time attributes column of data should be mapped to hopping windows.slide: is a duration specifying the duration between the start of sequential hopping windowssize: is a duration specifying the width of the hopping windows.offset: is an optional parameter to specify the offset which window start would be shifted by.
1 | #简单且常见的分维度分钟级别同时在线用户数,1 分钟输出一次,计算最近 5 分钟的数据 |
Group Window Aggregation
Deprecated.
Session
Windowing TVF
TVF doesn’t support Session mode, using group window aggregation instread.
Group Window Aggregation
| Group Window Function | Description |
|---|---|
| SESSION(time_attr, interval) | Defines a session time window. Session time windows do not have a fixed duration but their bounds are defined by a time interval of inactivity, i.e., a session window is closed if no event appears for a defined gap period. For example a session window with a 30 minute gap starts when a row is observed after 30 minutes inactivity (otherwise the row would be added to an existing window) and is closed if no row is added within 30 minutes. Session windows can work on event-time (stream + batch) or processing-time (stream). |
1 | #Session 时间窗口和滚动、滑动窗口不一样,其没有固定的持续时间,如果在定义的间隔期(Session Gap)内没有新的数据出现,则 Session 就会窗口关闭 |
CUMULATE
Windowing TVF
1 | CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size) |
data: is a table parameter that can be any relation with an time attribute column.timecol: is a column descriptor indicating which time attributes column of data should be mapped to cumulating windows.step: is a duration specifying the increased window size between the end of sequential cumulating windows.size: is a duration specifying the max width of the cumulating windows.sizemust be an integral multiple ofstep.offset: is an optional parameter to specify the offset which window start would be shifted by.
1 | #每天的截止当前分钟的累计 money(sum(money)),去重 id 数(count(distinct id))。每天代表渐进式窗口大小为 1 天,分钟代表渐进式窗口移动步长为分钟级别 |
Group Window Aggregation
Deprecated.
Troubleshooting
#https://www.cnblogs.com/yeyuzhuanjia/p/17942445
Web UI cannot be visited by external:
vim conf/flink-conf.yaml:
1 | rest.address: 0.0.0.0 |
High-Availability
Recommend working on Yarn
High-Availability on YARN is achieved through a combination of YARN and a high availability service.
Once a HA service is configured, it will persist JobManager metadata and perform leader elections.
YARN is taking care of restarting failed JobManagers. The maximum number of JobManager restarts is defined through two configuration parameters. First Flink’s yarn.application-attempts configuration will default 2. This value is limited by YARN’s yarn.resourcemanager.am.max-attempts, which also defaults to 2.
Note that Flink is managing the high-availability.cluster-id configuration parameter when deploying on YARN. Flink sets it per default to the YARN application id. You should not overwrite this parameter when deploying an HA cluster on YARN. The cluster ID is used to distinguish multiple HA clusters in the HA backend (for example Zookeeper). Overwriting this configuration parameter can lead to multiple YARN clusters affecting each other.
Configure high availability mode and ZooKeeper quorum in conf/flink-conf.yaml:
1 | high-availability: zookeeper |
Histroy Server
Flink has a history server that can be used to query the statistics of completed jobs after the corresponding Flink cluster has been shut down.
By default, this server binds to localhost and listens at port 8082.
Troubleshooting
#https://www.jianshu.com/p/877868b6f829
NoResourceAvailableException: Could not acquire the minimum required resources
1 | taskmanager.memory.process.size: 6048m |
Seatunnel
1 | cat /etc/profile.d/hadoop.sh |